Образовательный стандарт дисциплины "Системное моделирование"
Моделируем значения ![]() как нормально распределенную случайную величину по зависимости
как нормально распределенную случайную величину по зависимости
![]() , (4.8)
, (4.8)
где ![]() – нормированная нормально распределенная случайная величина, моделируемая с помощью алгоритма.
<
– нормированная нормально распределенная случайная величина, моделируемая с помощью алгоритма.
<
p>Осуществляя обратный по отношению к преобразованию Фишера переход, получим случайное значение коэффициента корреляции
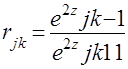 . (4.9)
. (4.9)
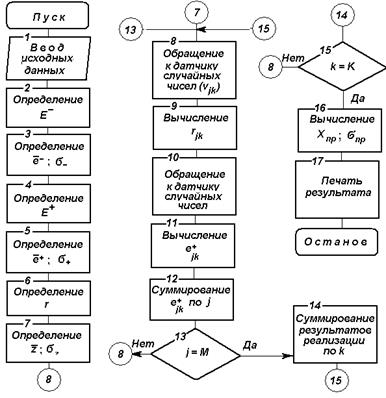
Рис. 4.3. Блок-схема алгоритма прогнозирования с использованием ориентированного процесса случайного блуждания
С учетом изложенного моделирование приращений на периоде упреждения включает выполнение следующих действий:
обращение к датчику нормированных нормально распределенных случайных чисел и получение ![]() ;
;
вычисление случайного значения ![]() по зависимостям (4.8) и (4.9);
по зависимостям (4.8) и (4.9);
обращение к датчику равномерно распределенных случайных чисел и получение числа ![]() ;
;
вычисление приращения ![]() по зависимости (4.6) при полученном в п. 2 значении коэффициента корреляции
по зависимости (4.6) при полученном в п. 2 значении коэффициента корреляции ![]() , определенном в п. 3 значении
, определенном в п. 3 значении ![]() .
.
Многократно имитируя приращения и используя зависимости (4.1) и (4.2), вычисляются характеристики прогноза. Блок-схема алгоритма изображена на рис.4.3.
К достоинствам рассмотренного метода прогнозирования относятся:
простота вычислительного алгоритма;
возможность использования при ограниченной на периоде основания информации (начиная с 7-9 значений динамического ряда);
простота оценивания точности прогноза (определения дисперсии).
4.2 Модифицированный имитационным моделированием метод экспоненциального сглаживания
Для прогнозирования характеристик образцов техники, математическое описание которых имеет вид
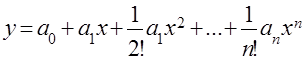 , (4.10)
, (4.10)
целесообразно применять метод экспоненциального сглаживания. Сложившаяся практика использования этого метода предполагает ограничение числа членов ряда Тейлора
![]() ,(4.11)
,(4.11)
аппроксимирующего выражение (4.10), несколькими членами ![]() .
.
В зависимости (4.11) ![]() –
– ![]() -я производная функции по переменной в точке
-я производная функции по переменной в точке ![]() ;
; ![]() ;
; ![]() – число наблюдений;
– число наблюдений; ![]() – значение величины шага упреждения.
– значение величины шага упреждения.
Для условий, когда ошибки прогнозирования не удовлетворяют заданным требованиям, можно осуществить анализ их источников. Известно [4], что точность прогнозной задачи можно определить по зависимости
![]() , (4.12)
, (4.12)
где 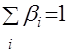 ;
;
![]() – погрешность, обусловленная приближенностью исходной информации;
– погрешность, обусловленная приближенностью исходной информации;
![]() – погрешность, связанная с методом прогнозирования;
– погрешность, связанная с методом прогнозирования;
![]() – погрешность, вызванная неточностью вычислений;
– погрешность, вызванная неточностью вычислений;
![]() – нерегулярная погрешность, обусловленная вероятностью непредсказуемых в настоящее время событий, влияющих на характер изменения прогнозируемой величины.
– нерегулярная погрешность, обусловленная вероятностью непредсказуемых в настоящее время событий, влияющих на характер изменения прогнозируемой величины.
Одной из наиболее весомых является методическая ошибка, зависящая от числа членов разложения. В работах [1], [2] приводятся аналитические зависимости для выполнения параметров аппроксимирующего многочлена при ![]() . Вывод таких зависимостей для
. Вывод таких зависимостей для ![]() представляет значительные трудности. Кроме того, любое увеличение числа членов выражения (4.11) влечет за собой потребность увеличения объема исходных данных, необходимых для определения оценок начальных значений коэффициентов
представляет значительные трудности. Кроме того, любое увеличение числа членов выражения (4.11) влечет за собой потребность увеличения объема исходных данных, необходимых для определения оценок начальных значений коэффициентов ![]() (методом наименьших квадратов или в более общем случае методом максимального правдоподобия), далее предлагается модификация метода экспоненциального сглаживания, основанная на принципах группового учета аргументов. Сущность метода заключается в том, что математическая модель объекта прогнозирования
(методом наименьших квадратов или в более общем случае методом максимального правдоподобия), далее предлагается модификация метода экспоненциального сглаживания, основанная на принципах группового учета аргументов. Сущность метода заключается в том, что математическая модель объекта прогнозирования
![]() ,
,
называемая в соответствии с терминологией работы [1] его «полным описанием», заменяется набором «частных описаний» вида
![]() .
.
По принятому критерию, значение которого вычисляется для каждого «частного описания», из множества ![]() отбирается некоторое число, называемое «свободой выбора», наиболее регулярных описаний, образующих подмножество
отбирается некоторое число, называемое «свободой выбора», наиболее регулярных описаний, образующих подмножество ![]() . Вычисленные значения промежуточных аргументов
. Вычисленные значения промежуточных аргументов ![]() принимаются в качестве аргументов «частных описаний» следующего уровня фильтрации, то есть
принимаются в качестве аргументов «частных описаний» следующего уровня фильтрации, то есть
![]() .
.
Аналогичная процедура повторяется до тех пор, пока величина критерия фильтрации уменьшается или увеличивается в зависимости от его содержания (при этом исходная информация делится на две выборки: обучающую и проверочную). Для практических расчетов в качестве такого критерия рекомендуется принимать среднеквадратическую ошибку аппроксимации модели на проверочной выборке, которая, как установлено в работе [10], при увеличении числа уровней фильтрации, а, следовательно, сложности модели, достигает экстремального значения. Сложность модели (измеряется числом ее членов), соответствующая экстремальному значению критерия, является оптимальной. На последнем уровне фильтрации фиксируется «частное описание», значение которого минимально. На предпоследнем уровне выбираются «частные описания», являющиеся аргументами последнего уровня, и т.д. Так как «частные описания» являются функцией двух аргументов, их коэффициенты легко определяются по небольшому количеству исходных данных. Исключая промежуточные переменные ![]() можно получить модель исследуемых характеристик объекта прогнозирования в виде аналога «полного описания»
можно получить модель исследуемых характеристик объекта прогнозирования в виде аналога «полного описания»
Другие рефераты на тему «Педагогика»:
Поиск рефератов
Последние рефераты раздела
- Тенденции развития системы высшего образования в Украине и за рубежом: основные направления
- Влияние здоровьесберегающего подхода в организации воспитательной работы на формирование валеологической грамотности младших школьников
- Характеристика компетенций бакалавров – психологов образования
- Коррекционная программа по снижению тревожности у детей младшего школьного возраста методом глинотерапии
- Формирование лексики у дошкольников с общим недоразвитием речи
- Роль наглядности в преподавании изобразительного искусства
- Активные методы теоретического обучения