Основные понятия и методы экономико-математического моделирования
Предположим, что между нашими величинами существует линейная зависимость.
Тогда расчеты лучше всего выполнить в Excel, используя статистические функции;
СРЗНАЧ – для вычисления средних значений;
ДИСП – для нахождения дисперсии;
СТАНДОТКЛОН – для определения среднего квадратичного отклонения;
КОРЕЛЛ – для вычисления коэффициента корреляции.
Корреляционный момент можно в
ычислить, найдя отклонения от средних значений для ряда X и ряда Y , затем при помощи функции СУММПРОИЗВ определить сумму их произведений, которую необходимо разделить на n-1.
Результаты вычислений можно свести в таблицу.
Параметры линейного однофакторного уравнения регрессии
| Показатели | X | Y |
| Среднее значение | 15 | 9,3 |
| Дисперсия | 14 | 6,08 |
| Среднее квадр. отклонение | 3,7417 | 2,4658 |
| Корреляционный момент | 8,96 | |
| Коэффициент корреляции | 0,9712 | |
| Параметры | b=0,64 | a = -0,3 |
В итоге наше уравнение будет иметь вид:
y = -0.3 + 0.64x
Используя это уравнение, можно найти расчетные значения Y и построить график (рис. 2.1).
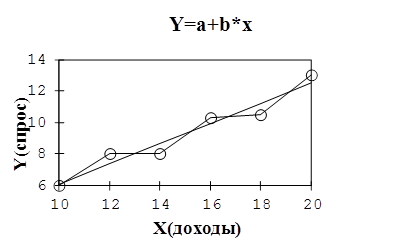
Рис. 2.1. Фактические и расчетные значения ![]()
Ломаная линия на графике отражает фактические значения Y, а прямая линия построена с помощью уравнения регрессии и отражает тенденцию изменения спроса в зависимости от дохода.
Однако встает вопрос, насколько значимы параметры a и b? Какова величина погрешности?
Оценка величины погрешности линейного однофакторного уравнения
Обозначим разность между фактическим значением результативного признака и его расчетным значением как ![]() :
:
![]() , где
, где
![]() фактическое значение y;
фактическое значение y;
![]() расчетное значение y,
расчетное значение y,
![]() – разность между ними.
– разность между ними.
2. В качестве меры суммарной погрешности выбрана величина:
![]() .
.
Для нашего примера S = 0.432.
Поскольку ![]() (среднее значение остатков) равно нулю, то суммарная погрешность равна остаточной дисперсии:
(среднее значение остатков) равно нулю, то суммарная погрешность равна остаточной дисперсии:
3. Остаточная дисперсия находится по формуле:
![]()
Для нашего примера![]() . Можно показать, что
. Можно показать, что
![]() .
.
Если ![]()
![]() то
то ![]()
![]() то
то ![]()
Таким образом, ![]() .
.
Легко заметить, что если ![]() , то
, то
![]()
Это соотношение показывает, что в экономических приложениях допустимая суммарная погрешность может составить не более 20% от дисперсии результативного признака ![]() .
.
4. Стандартная ошибка уравнения находится по формуле:
![]() , где
, где
![]() – остаточная дисперсия. В нашем случае
– остаточная дисперсия. В нашем случае ![]() .
.
5. Относительная погрешность уравнения регрессии вычисляется как:
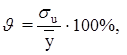
где ![]() стандартная ошибка;
стандартная ошибка;
![]() – среднее значение результативного признака.
– среднее значение результативного признака.
В нашем случае ![]() = 7.07%.
= 7.07%.
Если величина ![]() мала и отсутствует автокорреляция остатков, то прогнозные качества оцененного регрессионного уравнения высоки.
мала и отсутствует автокорреляция остатков, то прогнозные качества оцененного регрессионного уравнения высоки.
6. Стандартная ошибка коэффициента b вычисляется по формуле:
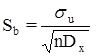
В нашем случае она равна ![]() .
.
Для вычисления стандартной ошибки коэффициента a используется формула:
![]()
В нашем примере ![]() .
.
Стандартные ошибки коэффициентов используются для оценивания параметров уравнения регрессии.
Коэффициенты считаются значимыми, если
![]()
В нашем примере 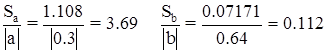
Коэффициент а не значим, т.к. указанное отношение больше 0.5, а относительная погрешность уравнения регрессии слишком высока – 26.7%.
Стандартные ошибки коэффициентов используются также для оценки статистической значимости коэффициентов при помощи t – критерия Стьюдента. Значения t – критерия Стьюдента содержатся в справочниках по математической статистике. В таблице 2.1 приводятся его некоторые значения.
Другие рефераты на тему «Экономико-математическое моделирование»:
Поиск рефератов
Последние рефераты раздела
- Выборочные исследования в эконометрике
- Временные характеристики и функция времени. Графическое представление частотных характеристик
- Автоматизированный априорный анализ статистической совокупности в среде MS Excel
- Биматричные игры. Поиск равновесных ситуаций
- Анализ рядов распределения
- Анализ состояния финансовых рынков на основе методов нелинейной динамики
- Безработица - основные определения и измерение. Потоки, запасы, утечки, инъекции в модели