Методы извлечения знаний
Алгоритм CLS циклически разбивает обучающие примеры на классы в соответствии с переменной, имеющей наибольшую классифицирующую силу. Каждое подмножество примеров (объектов), выделяемое такой переменной, вновь разбивается на классы с использованием следующей переменной с наибольшей классифицирующей способностью и т. д. Разбиение заканчивается,
когда в подмножестве оказываются объекты лишь од
ного класса. В ходе процесса формируется дерево решений. Пути движения по этому дереву от его корня к листьям определяют логические правила в виде цепочек конъюнкций.
Оценка эффективности алгоритма выполнялась на интеллектуальном анализе медицинских данных небольшого объёма - 74 записи. Из них были выявлены знания в количестве 9 продукций. Для увеличения практической значимости разрабатываемой системы (EasyGetKnowledge) намечается расширить ориентацию алгоритма извлечения на базы данных различного формата.
2.1.1 Алгоритм построения деревьев решений для системы автоматизированного извлечения знаний
Формально задача автоматического извлечения знаний из баз данных может быть описана следующим образом. Предметная область представляется в виде реляционной модели данных, которая описывается отношением R, являющимся подмножеством кортежей декартового произведения:
R(DX1, …, DXn, DY1, ,DYm) = {< x1, …, xn, y1, …, ym>│xi Є DXi,
yj Є DYj, I = 1 n, j = 1 m٨P(x1, …, xn, y1, …,ym) }, (2.1)
где xi –значения входных атрибутов Xi из домена DXi;
yi –значения выходных атрибутов Yi из домена DYi;
P(x1,…,xn,y1,…,ym)– предикат, описывающий условия отображения конкретной предметной области в кортежи значений атрибутов < x1,…,xn,y1,…,ym>.
Необходимо сформировать отображение в виде набора правил:
{X1,X2, ,Xn}-> {Y1,Y2,…,Ym} (2.2)
ставящих каждому входному набору значений {xi=DXi, i=1 n} в соответствие некоторый набор целевых значений {yj=DYj, j=1 m}. Полученные функциональные зависимости:
Yj = Fj(X1,X2,….,Xn), j=1 m (2.3)
должны быть верны для кортежей отношения (1) и могут быть использованы при нахождении выходных атрибутов Yj для новых значений входных атрибутов Xi (i=1 n).
Для автоматизированного извлечения знаний использовался метод CART (classification and regression trees) из класса методов деревьев решений. Данный подход является самым распространенным в настоящее время способом выявления, структурирования и графического представления логических закономерностей в данных. Его преимущества заключаются в следующем[33]:
• быстрый процесс обнаружения знаний;
• генерация правил в предметных областях, в которых трудно формализуются знания;
• извлечение правил на естественном языке;
• создание интуитивно понятной классификационной модели предметной области;
• прогноз с высокой точностью, сопоставимой с другими методами (статистическими и нейросетевыми);
• построение непараметрических моделей.
Хорошая эволюция и достигнутый уровень формализации методов послужили основанием использовать процедуру CART, как лучший из этого класса, в блоке извлечения знаний. В данном алгоритме можно выделить три операции, от реализации которых зависит его трудоёмкость и качество обнаружения знаний: сортировка источника данных при формировании множества условий U для атрибутов числового типа, вычисление критерия Gini [33] при разбиении узлов бинарного дерева, перемещение в таблице значительных объёмов информации при делении узла.
Покажем вычислительные затраты при классификации одного узла дерева. Пусть узлу, для которого осуществляется классификация, соответствует M объектов (строк) сводной таблицы. Каждая строка таблицы рассматривается как один пример обучающей выборки. Параметром N обозначим количество атрибутов таблицы без учёта целевого атрибута. Предположим, что в базе данных содержатся только атрибуты категорийного типа, имеющие в среднем Ncp значений.
Для определения необходимости последующего деления узла потребуется
M проверок. Рассмотрим случай, когда из узла порождаются узлы-потомки. В этом случае для каждого атрибута формируются 2Ncp-1-1 возможных условий ui принадлежит U (|U|=2Ncp-1-1) (2.4), которые определяют варианты разбиения узла. Эта операция реализуется M проверками. Отбор наилучшего варианта разбиения узла дерева проводится по наибольшей классифицирующей силе, вычисляемой по критерию Gini :
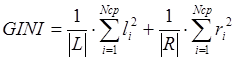 (2.4)
(2.4)
Из формулы (2.4) видно, что её вычислительная сложность состоит из суммы следующих операций: подсчёт элементов li, ri класса i (i=1 Ncp) в множествах L и R и вычисление индекса Gini. Подсчёт объектов каждого класса занимает M операций, а вычисление индекса Gini выполняется за 2∙Ncp+2 операций. Следовательно, классификация узла по условию ui и отбор наилучшего разбиения занимает в целом 2M + 2Ncp операций. Тогда для каждого категорийного атрибута потребуется (2M + 2Ncp)∙( 2Ncp-1-1) операций. А так как таблица имеет N атрибутов, то классификация одного узла без учёта разделения будет занимать (2M + 2Ncp)∙(2Ncp-1-1)∙N +M условных операций. На примере таблицы, содержащей 1000 строк, 10 категорийных атрибутов с 5 возможными значениями, разбиение корневого узла дерева потребует приблизительно 300 000 условных операций, что значительно меньше полного перебора.
В качестве предметной области для проведения интеллектуального анализа
рассмотрена медицинская диагностика. Часть данных (90%) использовалась для извлечения знаний, а остальные 10% - для оценки качества прогнозирования исходов лечения. При этом правильно было спрогнозировано 48 исходов лечения из 70. Для увеличения эффективности алгоритма планируется использование генетических алгоритмов для увеличение точности прогноза в узлах дерева содержащих небольшое количество элементов.
2.1.2 Интеллектуальный анализ данных Data Mining
Data Mining переводится как "добыча" или "раскопка данных". Нередко рядом с Data Mining встречаются слова "обнаружение знаний в базах данных" (knowledge discovery in databases) и "интеллектуальный анализ данных". Их можно считать синонимами Data Mining. Возникновение всех указанных терминов связано с новым витком в развитии средств и методов обработки данных.
До начала 90-х годов, казалось, не было особой нужды переосмысливать ситуацию в этой области. Все шло своим чередом в рамках направления, называемого прикладной статистикой . Теоретики проводили конференции и семинары, писали внушительные статьи и монографии, изобиловавшие аналитическими выкладками.
Вместе с тем, практики всегда знали, что попытки применить теоретические экзерсисы для решения реальных задач в большинстве случаев оказываются бесплодными. Но на озабоченность практиков до поры до времени можно было не обращать особого внимания - они решали главным образом свои частные проблемы обработки небольших локальных баз данных.
В связи с совершенствованием технологий записи и хранения данных на людей обрушились колоссальные потоки информационной в самых различных областях. Деятельность любого предприятия (коммерческого, производственного, медицинского, научного и т.д.) теперь сопровождается регистрацией и записью всех подробностей его деятельности. Стало ясно, что без продуктивной переработки данных образуют никому не нужный обьем информации.
Другие рефераты на тему «Программирование, компьютеры и кибернетика»:
Поиск рефератов
Последние рефераты раздела
- Основные этапы объектно-ориентированного проектирования
- Основные структуры языка Java
- Основные принципы разработки графического пользовательского интерфейса
- Основы дискретной математики
- Программное обеспечение системы принятия решений адаптивного робота
- Программное обеспечение
- Проблемы сохранности информации в процессе предпринимательской деятельности