Методы извлечения знаний
Информационная система - взаимосвязанные данные, содержащие все сведения о хозяйственной или иной деятельности предприятия. Такая система позволяет облегчить труд человека, повысить качество и достоверность обрабатываемой информации. Основу ИС составляют хранящиеся в ней данные. Хранящиеся в ИС данные должны быть легко доступны, чтобы предоставлять достоверную информацию в определенное время, к
онкретному лицу, в определенном месте и с ограниченными затратами.
Ценность информации в современном мире очень высока. В основе решения многих задач лежит обработка информации. С развитием экономики и ростом численности населения возрастает и объем взаимосвязанных данных, необходимых для решения коммерческих и административных задач. Для облегчения обработки информации создается ИС. Такая система в первую очередь призвана облегчить труд человека, но для этого она должна как можно лучше соответствовать очень сложной модели реального мира. Автоматизированными называют ИС, в которых применяют технические средства, в частности ЭВМ.
Ядром ИС являются хранимые в ней данные, которые должны быть легко доступны в том виде, в каком они нужны для конкретной производственной деятельности предприятия. ИС обязаны предоставлять достоверную информацию в определенное время, определенному лицу, в определенном месте и с ограниченными затратами.
Объектом называется элемент ИС, о котором хранится информация. Объект может быть реальным (например, человек, какой-либо предмет или населенный пункт) и абстрактным (например, событие, счет покупателя или изучаемый студентами курс). Каждый объект обладает определенным набором свойств, которые запоминаются в ИС.
БД представляет собой совокупность специальным образом организованных данных, которые находятся в памяти вычислительной системы и отображают состояние объектов и их взаимосвязей в рассматриваемой предметной области. БД обеспечивают надежное хранение информации в структурированном виде и своевременный доступ к ней. Практически любая современная организация нуждается в БД, удовлетворяющей те или иные потребности по хранению, управлению и администрированию данных.
1 ПОСТАНОВКА ЗАДАЧИ
В основу проектирования БД должны быть положены представления конечных пользователей конкретной организации - концептуальные требования к системе. Именно конечный пользователь в своей работе принимает решения с учетом получаемой в результате доступа к БД информации. От оперативности и качества этой информации будет зависеть эффективность работы организации.
При рассмотрении требований конечных пользователей необходимо принимать во внимание следующее:
- БД должна удовлетворять актуальным информационным потребностям организации. Получаемая информация должна по структуре и содержанию соответствовать решаемым задачам.
- БД должна удовлетворять выявленным и вновь возникающим требованиям конечных пользователей.
- БД должна легко расширяться при реорганизации и расширении предметной области.
Данные до включения в БД должны проверяться на достоверность.
Необходимо разработать АРМ мастера механического цеха, которая включает в себе базу данних, позволяющую:
· принимать заказы на изготовление деталей в виде таблицы;
· просматривать полную информацию по всем заказам в таблице, а также добавлять нужную Вам информацию;
· просматривать список деталей по заданому заказу, а также список операций по выбранной детали для производства;
· просматривать полную информации по станкам и инструменту;
· просматривать полную информацию по рабочему персоналу;
· просматривать составы бригады по ее номеру, и вывода отчета по рабочему персоналу;
· Полного просмотра информации ОАО им. М.В. «Фрунзе».
2 АНАЛИЗ МЕТОДОВ АВТОМАТИЗИРОВАННОГО ИЗВЛЕЧЕНИЯ ЗНАНИЙ ИЗ РЕЛЯЦИОННЫХ БАЗ ДАННЫХ
Рассматривается задача автоматического извлечения знаний из баз данных, решение которой ускорит создание интеллектуальных систем принятия решений. В настоящее время для ее решения предложено много методов, составляющих новую технологию Data Mining. Автоматизация извлечения знаний из баз данных должна учитывать следующую специфику:
Данные имеют неограниченный объем.
Данные являются разнородными (количественными, качественными, текстовыми).
Извлеченные знания должны быть конкретны и понятны.
Инструменты обнаружения знаний должны быть просты в использовании и работать при наличии простых данных.
2.1 Автоматизированное извлечение знаний из баз данных
Первоначально основным инструментом анализа данных были классические методы математической статистики, которые не могли эффективно обнаруживать скрытые закономерности в реальных данных. Главной причиной этому была концепция усреднения по выборке, приводящая к операциям над фиктивными величинами. Методы математической статистики оказались полезными главным образом для проверки заранее сформулированных гипотез (verification-driven data mining) и для "грубого" предварительного анализа, составляющего основу оперативной аналитической обработки данных (online analytical processing, OLAP).
В основу современных методов технологии Data Mining (discovery-driven data mining) положена концепция шаблонов, отражающих фрагменты многоаспектных взаимоотношений в данных. Эти шаблоны представляют собой закономерности, свойственные подвыборкам(классам) данных, которые могут быть компактно выражены в понятной человеку форме. Методы поиска шаблонов не ограничиваются рамками априорных предположений о структуре выборки и вида распределения значений анализируемых показателей. Важным достоинством технологии Data Mining является нетривиальность разыскиваемых шаблонов, т.е. они должны отражать неочевидные, неожиданные регулярности в данных, составляющие так называемые скрытые знания (hidden knowledge).
Существующие системы Data Mining [5] дорогостоящие и не ориентированы на решение задач принятия решений. Самыми известными являются See5/С5.0 (RuleQuest, Австралия), Clementine (Integral Solutions, Великобритания), SIPINA (University of Lyon, Франция), IDIS (Information Discovery, США), KnowledgeSeeker (ANGOSS, Канада). Стоимость этих систем варьируется от 1 до 10 тыс. долл. Поэтому в данной работе рассматривается создание подобной системы автоматического извлечения знаний из баз данных разного формата с возможностью принятия решения на основе выявленных знаний. Структура разрабатываемой системы приведена на рис. 2.1.
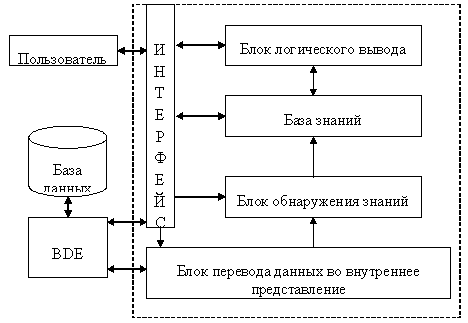
Рис. 2.1 - Структура системы извлечения знаний из баз данных
Пользовательский интерфейс обеспечивает доступ ко всем возможностям
системы и управляет процессами извлечения знаний и принятием решений. Качество обнаружения знаний во многом зависит от участии пользователя. Первичная подготовка данных осуществляется в блоке перевода данных во внутреннее представление, учитывающие особенности алгоритмов извлечения знаний. Блок обнаружения знаний основан на алгоритме CLS [6], который выявляет скрытые закономерности в данных. Эти закономерности формируются в виде деревьев решений и сохраняются в базе знаний в форме продукционных правил. Извлечённые знания могут пополнять существующую базу знаний некоторой экспертной системы или сразу использоваться для выработки рекомендаций по достижению поставленных целей.
Другие рефераты на тему «Программирование, компьютеры и кибернетика»:
- Графическое моделирование зависимостей максимальной высоты и длины полёта тела от коэффициента сопротивления среды
- Автоматизированные системы управления обработки информации в торговле
- Моделирование линейных непрерывных систем в среде LabVIEW
- Выполнение расчетов и оформление технической документации с использованием текстовых редакторов и электронных таблиц
- Основы работы с использованием системы AutoCAD
Поиск рефератов
Последние рефераты раздела
- Основные этапы объектно-ориентированного проектирования
- Основные структуры языка Java
- Основные принципы разработки графического пользовательского интерфейса
- Основы дискретной математики
- Программное обеспечение системы принятия решений адаптивного робота
- Программное обеспечение
- Проблемы сохранности информации в процессе предпринимательской деятельности