Применение математики в статистике
Коэффициент b1 характеризует наклон линии регрессии. b1 = 0,00873. Это означает, что при увеличении Х на единицу ожидаемое значение Y возрастет на 0,00873. То есть регрессионная модель указывает на то, что каждый новый посетитель магазина в среднем увеличивает недельную выручку магазина на 0,00873 у.е. (или можно сказать, что ожидаемый прирост ежедневной выручки составит 8,73 у.е. при привлеч
ении в магазин 100 дополнительных посетителей). Отсюда b1 может быть интерпретирован как прирост ежедневной выручки, который варьирует в зависимости от числа посетителей магазина.
Свободный член уравнения b0 = +2,423 у.е., это – эначение Y при X, равном нулю. Поскольку маловероятно число посетителей магазина, равное нулю, то можно интерпретировать b0 как меру влияния на величину ежедневной выручки других факторов, не включенных в уравнение регрессии.
Регрессионная модель может быть использована для прогноза объема ежедневной выручки. Например, мы хотим использовать модель для предсказания средней ежедневной выручки магазина, который посетят 600 покупателей.
Когда мы используем регрессионные модели для прогноза, важно помнить, что обсуждаются только значения независимых переменных, находящиеся в пределах от наименьшего до наибольшего значений факторного признака, используемые при создании модели. Отсюда, когда мы предсказываем Y по заданным значениям X, мы можем интерполировать значения в пределах заданных рангов Х, но мы не можем экстраполировать вне рангов X. Например, когда используется число посетителей для прогноза дневной выручки магазина, то мы знаем из данных примера, что их число находится в пределах от 420 до 1010. Следовательно, предсказание недельной выручки может быть сделано только для магазинов с числом покупателей от 420 до 1010 чел.
Хотя метод наименьших квадратов дает нам линию регрессии, которая обеспечивает минимум вариации, регрессионное уравнение не является идеальным в смысле предсказания, поскольку не все значения зависимого признака Y удовлетворяют уравнению регрессии. Нам необходима статистическая мера вариации фактических значений Y от предсказанных значений Y. Эта мера в то же время является средней вариацией каждого значения относительно среднего значения Y.Мера вариации относительно линии регрессии называется стандартной ошибкой оценки.
Для проверки того, насколько хорошо независимая переменная предсказывает зависимую переменную в нашей модели, необходим расчет ряда мер вариации. Первая из них – общая (полная) сумма квадратов отклонений результативного признака от средней – есть мера вариации значений Y относительно их среднего `Y. В регрессионном анализе общая сумма квадратов может быть разложена на объясняемую вариацию или сумму квадратов отклонений за счет регрессии и необъясняемую вариацию или остаточную сумму квадратов отклонений.
Сумма квадратов отклонений вследствие регрессии это – сумма квадратов разностей между `y (средним значением Y) и `yx (значением Y, предсказанным по уравнению регрессии). Сумма квадратов отклонений, не объясняемая регрессией (остаточная сумма квадратов), – это сумма квадратов разностей y и `yx. Эти меры вариации могут быть представлены следующим образом (табл.8):
Таблица 8
|
Общая сумма квадратов (ST) |
= |
Сумма квадратов за счет регрессии (SR) |
+ |
Остаточная сумма квадратов (SE) |
Следовательно, 91,3% вариации еженедельной выручки магазинов могут быть объяснены числом покупателей, варьирующим от магазина к магазину. Только 8,7% вариации можно объяснить иными факторами, не включенными в уравнение регрессии.
В простой линейной регрессии г имеет тот же знак, что и b1, Если b1 > 0, то r > 0; если b1 < 0, то r < 0, если b1 = 0, то r = 0.
В нашем примере r2 = 0,913 и b1 > 0, коэффициент корреляции r = 0,956. Близость коэффициента корреляции к 1 свидетельствует о тесной положительной связи между выручкой магазина от продажи пива и числом посетителей.
Мы интерпретировали коэффициент корреляции в терминах регрессии, однако корреляция и регрессия – две различные техники. Корреляция устанавливает силу связи между признаками, а регрессия – форму этой связи. В ряде случаев для анализа достаточно найти меру связи между признаками, без использования одного из них в качестве факторного признака для другого.
3. Доверительные интервалы для оценки
Доверительные интервалы для оценки неизвестного генерального значения `yген(myх) и индивидуального значения `yi.
Поскольку в основном для построения регрессионных моделей используются данные выборок,то зачастую интерпретация взаимоотношений между переменными в генеральной совокупности базируется на выборочных результатах.
Как было сказано выше, регрессионное уравнение используется для прогноза значений Y по заданному значению X. В нашем примере показано, что при 600 посетителях магазина сумма выручки могла бы быть 7,661 у. е. Однако это значение – только точечная оценка истинного среднего значения. Мы знаем, что для оценки истинного значения генерального параметра возможна интервальная оценка.
Доверительный интервал для оценки неизвестного генерального значения `yген(myх) имеет вид
![]()
где
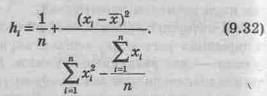
Здесь `yx – предсказанное значение Y
(`yx==b0+b1yi);
Syx – стандартная ошибка оценки;
п – объем выборки;
хi – заданное значение X.
Легко видеть, что длина доверительного интервала зависит от нескольких факторов. Для заданного уровня значимости a увеличение вариации вокруг линии регрессии, измеряемой стандартной ошибкой оценки, увеличивает длину интервала. Увеличение объема выборки уменьшит длину интервала. Более того, ширина интервала также варьирует с различными значениями X. Когда оценивается `yx по значениям X, близким к `x, то интервал тем уже, чем меньше абсолютное отклонение хi от `x (рис. 9.5).
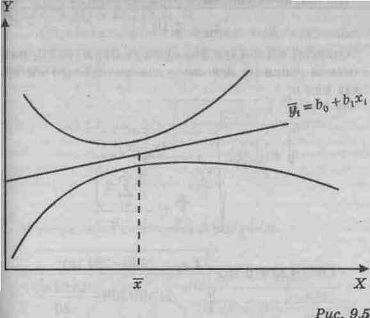
Когда оценка осуществляется по значениям X, удаленным от среднего `x, то длина интервала возрастает.
Рассчитаем 95%-й доверительный интервал для среднего значения выручки во всех магазинах с числом посетителей, равным 600. По данным нашего примера уравнение регрессии имеет вид
`yx = 2,423 + 0,00873x:
и для `xi= 600 получим `yi; =7,661, а также
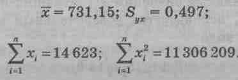
По таблице Стьюдента t18 = 2,10.
Отсюда, используя формулы (9.31) и (9.32), рассчитаем границы искомого доверительного интервала для myx
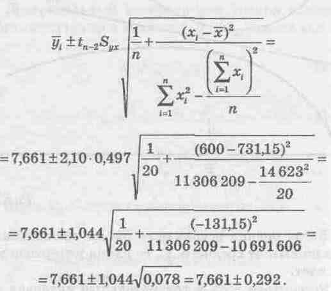
Итак, 7,369 £ myx £7,953.
Следовательно, наша оценка состоит в том, что средняя дневная выручка находится между 7,369 и 7,953 у.е. для всех магазинов с 600 посетителями.
Другие рефераты на тему «Математика»:
Поиск рефератов
Последние рефераты раздела
- Анализ надёжности и резервирование технической системы
- Алгоритм решения Диофантовых уравнений
- Алгебраическое доказательство теоремы Пифагора
- Алгоритм муравья
- Векторная алгебра и аналитическая геометрия
- Зарождение и создание теории действительного числа
- Вероятностные процессы и математическая статистика в автоматизированных системах