Математические методы экономических исследований
Пусть операция (задача) является управляемой, т.е. выбираются какие-то параметры, которые влияют на ход и исход. На каждом шаге выбирается какое-то решение, от которого зависит выигрыш на данном шаге и выигрыш на операции в целом, - шаговое управление. Совокупность всех шаговых управлений есть управление операцией (задачей) в целом. Обозначив его Х, а шаговое управление х1, x2, ., хm, имеем: <
p>![]() , хi - может принимать любые значения (числа, векторы, функции и т.д.).
, хi - может принимать любые значения (числа, векторы, функции и т.д.).
Требуется найти такое управление Х, при котором выигрыш W обращается в максимум: 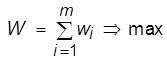 .
.
x = x *, при котором это случается, называется оптимальным управлением: ![]() .
.
Пусть ![]() , максимум берется по всем управлениям х, (возможным в данных условиях), т.е. возможна запись:
, максимум берется по всем управлениям х, (возможным в данных условиях), т.е. возможна запись: ![]() .
.
Принцип решения задачи ДП.
Метод ДП не предполагает, что каждый шаг оптимизируется отдельно, независимо от других.
Пусть, например, планируется работа группы предприятий, часть из которых выпускает предметы потребления, а остальные производят для них машины. Задача - за m лет получить максимальный объем предметов потребления.
Пусть планируются инвестиции на первый год. Если исходить из узких интересов этого шага (года), то можно было бы вложить все наличные средства в производство предметов потребления. Но такое решение не было бы правильным (эффективным) с точки зрения операции в целом. Конечно, вкладывая средства в производство машин, мы сокращаем объем производства предметов потребления в данном году, но, однако, вместе с этим создаются условия для увеличения производства в последующие годы.
Итак, планируя многошаговую задачу, необходимо выбирать управление на каждом шагу с учетом всех его будущих последствий на еще предстоящих шагах.
Управление на i-том шаге выбирается так, чтобы была максимальной сумма выигрышей на всех оставшихся до конца шагах плюс данный.
Однако, последний шаг является исключением из этого правила. Здесь можно планировать так, чтобы он сам, как таковой, принес наибольшую выгоду.
Следовательно, процесс ДП обычно разворачивается от конца к началу, т.е. сначала планируется m-й шаг. Но как его спланировать, если не знаем, чем кончается предпоследний шаг. Как быть?
Планируя последний шаг, нужно сделать разные предположения о том, чем кончится предпоследний (m-1)-й шаг, и для каждого из этих предположений найти условное оптимальное управление на m-ом шаге [условное, так как оно выбирается, исходя из условия, что предпоследний шаг кончился так-то и так-то (каким-то образом)].
Предположим, что это сделано, и для каждого из возможных исходов предпоследнего шага известно условное оптимальное управление и соответствующий ему условный оптимальный выигрыш на m - ом шаге.
Теперь можно оптимизировать управление на предпоследнем (m-1)-ом шаге. Снова делаем возможные предположения о том, чем может кончиться предыдущий (m-2)-й шаг и для каждого из этих предположений находим такое управление на (m-1)-ом шаге, при котором выигрыш за последние два шага ( m-й уже оптимизирован) максимален. Так находятся для каждого исхода (m-2)-го шага условное оптимальное управление на (m-1)-м шаге и условный оптимальный выигрыш на двух последних шагах. И так, "пятясь назад", оптимизируем управление на (m-2)-м шаге и т.д., пока не дойдем до первого. Предположим, что все условные оптимальные управления и выигрыши за весь" хвост" процесса (на всех шагах, начиная от данного и до конца) известны. Теперь можно найти не условные оптимальные управления x* и w*.
Действительно, пусть известно, что в каком-то состоянии S0 управляемая система (объект управления S) была в начале первого шага. Тогда можно выбрать оптимальное управление х1* на первом шаге. Применив его, меняем состояние системы на некоторое новое S1*. В этом состоянии подходим ко второму шагу. Тогда тоже известно условное оптимальное управление x2*, которое к концу второго шага переводит систему в состояние S2* и т.д. Оптимальный выигрыш w* за всю операцию известен, так как именно на основе его максимальности выбиралось управление на первом шаге.
Таким образом, в процессе оптимизации управления методом ДП многошаговый процесс "проходится" дважды:
· от конца к началу - поиск условных оптимальных управлений и выигрышей за оставшийся "хвост" процесса;
· от начала к концу - осуществляется "чтение" уже готовых рекомендаций и поиск безусловного оптимального управления x*, состоящего из оптимальных шаговых управлений x1*, x2*, ., xm*.
Задача о распределении ресурсов
Имеется некий запас ресурсов (средств) К, который нужно распределить между предприятиями А1, А2, ., Аm. Каждое i-ое предприятие при вложении в него каких-то средств x приносит доход в виде функции ![]() . Все
. Все ![]() заданы (пусть они неубывающие). Как распределить средства К между Ai (i =1,2, .,m), чтобы в сумме они дали максимальный доход?
заданы (пусть они неубывающие). Как распределить средства К между Ai (i =1,2, .,m), чтобы в сумме они дали максимальный доход?
Здесь нет параметра времени. Однако, операцию распределения средств можно мысленно развернуть в какой-то последовательности, считая за первый шаг вложение в предприятие А1, за второй - вложение в предприятие А2 и т.д.
Управляемая система S в данном случае - это ресурсы (средства). Состояние системы S перед каждым шагом характеризуется одним числом S -наличным запасом еще не вложенных средств.
Шаговыми управлениями являются средства х1, x2, ., хm, выделяемые конкретным предприятиям.
Требуется найти оптимальное управление, т.е. совокупность х1, x2, ., хm, при которой суммарный доход максимален:
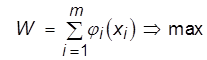 .
.
Решение в общем виде
Находим для каждого i-го шага условный оптимальный выигрыш (от этого шага и далее до конца), если к данному шагу подошли с запасом средств S. Обозначаем условный оптимальный выигрыш wi(S), а соответствующее ему условное оптимальное управление - средства, вкладываемые в i-е предприятие, - xi(S).
Начинаем оптимизацию с последнего m-го шага.
Пусть подошли к этому шагу с остатком средств S. Вкладываем всю сумму S целиком в предприятие Аm. Следовательно, условное оптимальное управление на m-ом шаге: отдать последнему предприятию все имеющиеся средства S:
![]() ,
,
а условный оптимальный выигрыш:
![]() .
.
Задаваясь последовательностью значений S (располагая их достаточно тесно), для каждого значения S будем знать xm(S) и wm(S). Последний шаг оптимизирован.
Переходим к предпоследнему (m-1)-му шагу. Пусть подошли к нему с запасом средств S. Обозначим wm-1(S) условный оптимальный выигрыш на двух последних шагах: (m-1)-ом и m-ом (последний оптимизирован). Если на (m-1)-ом шаге (m-1)-му предприятию выделим средств x, то на последний останется S-x. Выигрыш на двух последних шагах будет:
Другие рефераты на тему «Экономико-математическое моделирование»:
Поиск рефератов
Последние рефераты раздела
- Выборочные исследования в эконометрике
- Временные характеристики и функция времени. Графическое представление частотных характеристик
- Автоматизированный априорный анализ статистической совокупности в среде MS Excel
- Биматричные игры. Поиск равновесных ситуаций
- Анализ рядов распределения
- Анализ состояния финансовых рынков на основе методов нелинейной динамики
- Безработица - основные определения и измерение. Потоки, запасы, утечки, инъекции в модели