Арифметическое кодирование. Кодирование длин повторений
Тепеpь повтоpим действия кодера:
вначале [0.0 - 1.0);
после пpосмотpа [0.8 - 1.0).
Исключим из результата кодирования влияние теперь уже известного первого символа Р, для этого вычтем из результата кодирования нижнюю границу диапазона, отведенного для Р, – 0,8030349772 – 0.8 = =0,0030349772 – и разделим полученный результат на ширину интервала, отведенного для Р, b>– 0.2. В результате получим 0,0030349772 / 0,2 = =0,015174886. Это число целиком вмещается в интервал, отведенный для буквы А, – [0 – 0,1) , следовательно, вторым символом декодированной последовательности будет А.
Поскольку теперь мы знаем уже две декодированные буквы - РА, исключим из итогового интервала влияние буквы А. Для этого вычтем из остатка 0,015174886 нижнюю границу для буквы А 0,015174886 – 0.0 = =0,015174886 и разделим результат на ширину интервала, отведенного для буквы А, то есть на 0,1. В результате получим 0,015174886/0,1=0,15174886. Результат лежит в диапазоне, отведенном для буквы Д, следовательно, очередная буква будет Д.
Исключим из результата кодирования влияние буквы Д. Получим (0,15174886 – 0,1)/0,1 = 0,5174886. Результат попадает в интервал, отведенный для буквы И, следовательно, очередной декодированный символ – И, и так далее, пока не декодируем все символы: Декодируемое Символ Границы Ширина число на выходе нижняя верхняя интервала0,8030349772 Р 0.8 1.0 0.20,015174886 А 0.0 0.1 0.10,15174886 Д 0.1 0.2 0.10,5174886 И 0.3 0.6 0.30,724962 О 0,7 0,8 0,10,24962 В 0,2 0,2 0,10,4962 И 0,3 0,6 0,30,654 З 0,6 0,7 0,10,54 И 0,3 0,6 0,30,8 Р 0,6 0,8 0,20.0 Конец декодирования
Это основная идея арифметического кодирования, его практическая реализация несколько сложнее. Некоторые проблемы можно заметить непосредственно из приведенного примера.
Первая состоит в том, что декодеру нужно обязательно каким-либо образом дать знать об окончании процедуры декодирования, поскольку остаток 0,0 может означать букву а или последовательность аа, ааа, аааа и т.д. Решить эту проблему можно двумя способами.
Во-первых, кроме кода данных можно сохранять число, представляющее собой размер кодируемого массива. Процесс декодирования в этом случае будет прекращен, как только массив на выходе декодера станет такого размера.
Другой способ – включить в модель источника специальный символ конца блока, например #, и прекращать декодирование, когда этот символ появится на выходе декодера.
Вторая проблема вытекает из самой идеи арифметического кодирования и состоит в том, что окончательный результат кодирования – конечный интервал – станет известен только по окончании процесса кодирования. Следовательно, нельзя начать передачу закодированного сообщения, пока не получена последняя буква исходного сообщения и не определен окончательный интервал? На самом деле в этой задержке нет необходимости. По мере того, как интервал, представляющий результат кодирования, сужается, старшие десятичные знаки его (или старшие биты, если число записывается в двоичной форме) перестают изменяться (посмотрите на приведенный пример кодирования). Следовательно, эти разряды (или биты) уже могут передаваться. Таким образом, передача закодированной последовательности осуществляется, хотя и с некоторой задержкой, но последняя незначительна и не зависит от размера кодируемого сообщения.
И третья проблема – это вопрос точности представления. Из приведенного примера видно, что точность представления интервала (число десятичных разрядов, требуемое для его представления) неограниченно возрастает при увеличении длины кодируемого сообщения. Эта проблема обычно решается использованием арифметики с конечной разрядностью и отслеживанием переполнения разрядности регистров.
Кодирование длин повторений
Кодирование длин участков (или повторений) может быть достаточно эффективным при сжатии двоичных данных, например, черно-белых факсимильных изображений, черно-белых изображений, содержащих множество прямых линий и однородных участков, схем и т.п. Кодирование длин повторений является одним из элементов известного алгоритма сжатия изображений JPEG.
Идея сжатия данных на основе кодирования длин повторений состоит в том, что вместо кодирования собственно данных подвергаются кодированию числа, соответствующие длинам участков, на которых данные сохраняют неизменное значение.
Предположим, что нужно закодировать двоичное (двухцветное) изображение размером 8 х 8 элементов, приведенное на рис. 1.
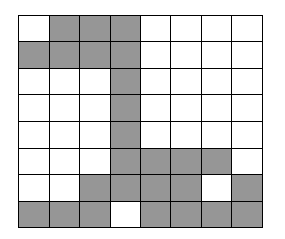 |
Рис. 1
Просканируем это изображение по строкам (двум цветам на изображении будут соответствовать 0 и 1), в результате получим двоичный вектор данных
X= (0111000011110000000100000001000000010000000111100011110111101111)
длиной 64 бита (скорость исходного кода составляет 1 бит на элемент изображения).
Выделим в векторе X участки, на которых данные сохраняют неизменное значение, и определим их длины. Результирующая последовательность длин участков - положительных целых чисел, соответствующих исходному вектору данных X, - будет иметь вид r = (1, 3, 4, 4, 7, 1, 7, 1, 7, 1, 7, 4, 3, 4, 1, 4, 1, 4).
Теперь эту последовательность, в которой заметна определенная повторяемость (единиц и четверок гораздо больше, чем других символов), можно закодировать каким-либо статистическим кодом, например, кодом Хаффмена без памяти, имеющим таблицу кодирования (табл. 2)
Таблица 2
|
Кодер | |
|
Длина участка |
Кодовое слово |
|
4 |
0 |
|
1 |
10 |
|
7 |
110 |
|
3 |
111 |
Для того, чтобы указать, что кодируемая последовательность начинается с нуля, добавим в начале кодового слова префиксный символ 0. В результате получим кодовое слово B (r) = (0100011010110101101011001110100100) длиной в 34 бита, то есть результирующая скорость кода R составит 34/64, или немногим более 0,5 бита на элемент изображения. При сжатии изображений большего размера и содержащих множество повторяющихся элементов эффективность сжатия может оказаться существенно более высокой.
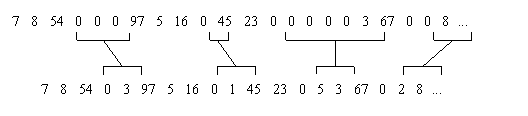
Ниже приведен другой пример использования кодирования длин повторений, когда в цифровых данных встречаются участки с большим количеством нулевых значений. Всякий раз, когда в потоке данных встречается “ноль”, он кодируется двумя числами. Первое - 0, являющееся флагом начала кодирования длины потока нулей, и второе – количество нулей в очередной группе. Если среднее число нулей в группе больше двух, будет иметь место сжатие. С другой стороны, большое число отдельных нулей может привести даже к увеличению размера кодируемого файла:
 |
Другие рефераты на тему «Коммуникации, связь и радиоэлектроника»:
- Частотомер многофункциональный на однокристальном микроконтроллере АТ89С2051
- Схема процесса автоматизированного проектирования РЭС. Структура и классификация проектных задач
- Проектирование активных фильтров с использованием активных резонаторов
- История развития твердотельной электроники
- Анализ преимуществ и недостатков электронных коммуникаций
Поиск рефератов
Последние рефераты раздела
- Микроконтроллер системы управления
- Разработка алгоритмического и программного обеспечения стандарта IEEE 1500 для тестирования гибкой автоматизированной системы в пакете кристаллов
- Разработка базы данных для информатизации деятельности предприятия малого бизнеса Delphi 7.0
- Разработка детектора высокочастотного излучения
- Разработка микропроцессорного устройства для проверки и диагностики двигателя внутреннего сгорания автомобиля
- Разработка микшерного пульта
- Математические основы теории систем