Автоматизация учета основных средств на предприятии
Широкие возможности компьютеров разных классов и моделей позволяют реализовать любые конфигурации сложных сетевых информационных систем. Аппаратные характеристики ЭВМ влияют на выбор системного и прикладного программного обеспечения. Высокий уровень техники дает возможность использовать и более качественную программную продукцию с большим количеством функций. Развитие программного обеспечения а
втоматизированного рабочего места (АРМ) экономиста постоянно совершенствует функции пользователя, повышает производительность его труда, одновременно расширяя масштабы деятельности. Совокупный эффект от качества программно-технического оснащения множества АРМ сказывается на процессах управления организацией в целом, на ее доходности и стабильности функционирования.
Что же касается конкретно нашей задачи, то с ней ситуация такова: основная часть АРМ бухгалтера уже готова и продумана в АСУ 1С Бухгалтерия. Наша задача организовать удобный интерфейс для нашего дополнительного блока, который позволит максимально эффективно проводить требуемые операции.
2. Проектная часть
2.1 Информационное обеспечение комплекса задач
2.1.1 Инфологическая (информационная) модель (схема данных) и ее описание
Для построения модели данных удобно воспользоваться языком диаграмм "сущность-связь".
Диаграммы "сущность-связь" (ERD) предназначены для разработки моделей данных и обеспечивают стандартный способ определения данных и отношений между ними. Фактически с помощью ERD осуществляется детализация хранилищ данных проектируемой системы, а также документируются сущности системы и способы их взаимодействия, включая идентификацию объектов, важных для предметной области (сущностей), свойств этих объектов (атрибутов) и их отношений с другими объектами (связей).
СУЩНОСТЬ представляет собой множество экземпляров реальных или абстрактных объектов (людей, событий, состояний, идей, предметов и т.п.), обладающих общими атрибутами или характеристиками. Любой объект системы может быть представлен только одной сущностью, которая должна быть уникально идентифицирована.
ОТНОШЕНИЕ в самом общем виде представляет собой связь между двумя и более сущностями. Именование отношения осуществляется с помощью грамматического оборота глагола (ИМЕЕТ, ОПРЕДЕЛЯЕТ, МОЖЕТ ВЛАДЕТЬ и т.п.).
Другими словами, сущности представляют собой базовые типы информации, хранимой в базе данных, а отношения показывают, как эти типы данных взаимоувязаны друг с другом. Введение подобных отношений преследует две основополагающие цели:
обеспечение хранения информации в единственном месте (даже если она используется в различных комбинациях);
использование этой информации различными приложениями.
Для идентификации требований, в соответствии с которыми сущности вовлекаются в отношения, используются СВЯЗИ. Каждая связь соединяет сущность и отношение и может быть направлена только от отношения к сущности.
ЗНАЧЕНИЕ связи характеризует ее тип и, как правило, выбирается из следующего множества:
{"O или 1", "0 или более", "1", "1 или более", "p: q" (диапазон) }.
Пара значений связей, принадлежащих одному и тому же отношению, определяет тип этого отношения. Практика показала, что для большинства приложений достаточно использовать следующие типы отношений:
1*1 (один-к-одному). Отношения данного типа используются, как правило, на верхних уровнях иерархии модели данных, а на нижних уровнях встречаются сравнительно редко.
1*n (один-к-многим). Отношения данного типа являются наиболее часто используемыми.
n*m (многие-к-многим). Отношения данного типа обычно используются на ранних этапах проектирования с целью прояснения ситуации. В дальнейшем каждое из таких отношений должно быть преобразовано в комбинацию отношений типов 1 и 2 (возможно, с добавлением вспомогательных сущностей и с введением новых отношений).
Разработка ERD включает следующие основные этапы:
Идентификация сущностей, их атрибутов, а также первичных и альтернативных ключей.
Идентификация отношений между сущностями и указание типов отношений.
Разрешение неспецифических отношений (отношений n*m).
Этап 1 является определяющим при построении модели, его исходной информацией служит содержимое хранилищ данных, определяемое входящими и выходящими в/из него потоками данных. Его единственное хранилище ДАННЫЕ О ПЕРСОНАЛЕ должно содержать информацию о всех сотрудниках: их имена, адреса, должности, оклады и т.п.
Первоначально осуществляется анализ хранилища, включающий сравнение содержимого входных и выходных потоков и создание на основе этого сравнения варианта схемы хранилища.
Следующий шаг - упрощение схемы при помощи нормализации (удаления повторяющихся групп). Единственным способом нормализации является расщепление данной схемы на две, являющиеся более простыми.
Определение отношений включает выявление связей, для этого отношение должно быть проверено в обоих направлениях следующим образом: выбирается экземпляр одной из сущностей и определяется, сколько различных экземпляров второй сущности может быть с ним связано, и наоборот.
Этап 2 предназначен для разрешения неспецифических (многие ко многим) отношений. Для этого каждое неспецифическое отношение преобразуется в два специфических отношения с введением новых (а именно, ассоциативных) сущностей.
По существу информационно-логическая модель представляет собой иллюстрированную, развернутую, подробную функциональную спецификацию будущей системы.
Инфологическая модель должна выражать информацию о предметной области в виде, независимом от используемой СУБД. Эта модель отражает в естественной и удобной для разработчиков и других пользователей форме информационно-логический уровень абстрагирования, связанный с фиксацией и описанием объектов предметной области, их свойств и их взаимосвязей. Инфологические модели данных используются на ранних стадиях проектирования для описания структур данных в процессе разработки приложения, см. рис 2.1.
Далее на рис.2.2 представлено схематичное изображение потоков данных в системе.

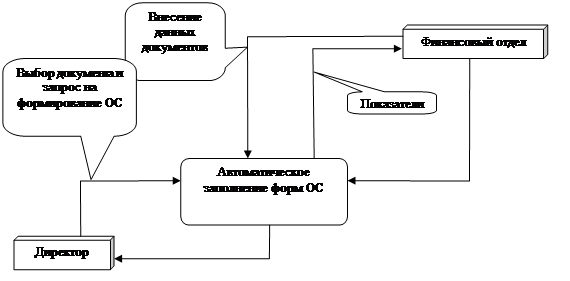
Рисунок 2.1
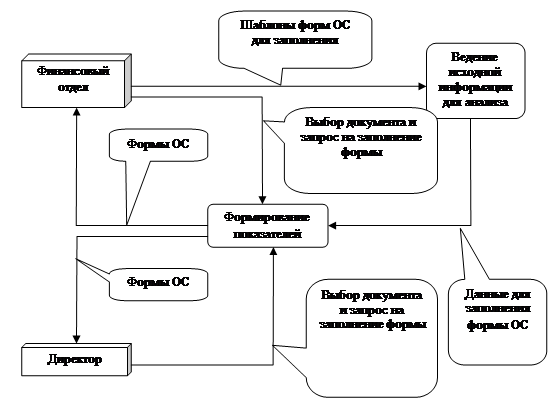
Рисунок 2.2.
Что касается нашего случая построения схемы данных, то для ее разработки использовалась уже готовая модель, которая имелась в основной АСУ, а также сами шаблоны унифицированных форм, которые позволяли отобрать необходимые для работы данные.
В структуре данной модели присутствуют: две внешних сущности - “Директор”, “Финансовый отдел"; два процесса - “Ведение исходной информации для заполнения форм”, “Заполнение форм ОС”.
Разработанная схема данных представлена на рис.2.3.
2.1.2 Используемые классификаторы и системы кодирования
Другие рефераты на тему «Программирование, компьютеры и кибернетика»:
Поиск рефератов
Последние рефераты раздела
- Основные этапы объектно-ориентированного проектирования
- Основные структуры языка Java
- Основные принципы разработки графического пользовательского интерфейса
- Основы дискретной математики
- Программное обеспечение системы принятия решений адаптивного робота
- Программное обеспечение
- Проблемы сохранности информации в процессе предпринимательской деятельности