Анализ и оптимизация цифровой системы связи
При описании процедуры кодирования и декодирования циклическим кодом удобно использовать математический аппарат, основанный на сопоставлении множества кодовых слов с множеством степенных полиномов. Этот аппарат позволяет выявить для циклического кода более простые операции кодирования и декодирования.
Среди всех полиномов, соответствующих кодовым словам циклического кода, имеется ненулевой
полином P(x) наименьшей степени. Этот полином полностью определяет соответствующий код и поэтому называется порождающим.
Степень порождающего полинома P(x) равна n - m, свободный член всегда равен единице.
Порождающий полином является делителем всех полиномов, соответствующих кодовым словам циклического кода.
Нулевая комбинация обязательно принадлежит любому линейному циклическому коду и может быть записана как (xn Å 1) mod (xn Å 1) = 0. Следовательно, порождающий полином Р(x) должен быть делителем бинома xn Å 1.
Это даёт конструктивную возможности построения циклического кода заданной длины n: любой полином, являющийся делителем бинома xn Å 1, можно использовать в качестве порождающего.
При построении циклических кодов, пользуются таблицами разложения биномов xn Å 1 на неприводимые полиномы, т.е. полиномы, которые нельзя представить в виде произведения двух других полиномов (см. приложение А).
Любой неприводимый полином, входящий в разложение бинома xn Å 1, а также любое произведение неприводимых полиномов может быть выбрано в качестве порождающего полинома, что дает соответствующий циклический код.
Для построения систематического циклического кода используется следующее правило построения кодовых слов
![]() ,
,
где R(x) – остаток от деления m(x)×xn-m на Р(x).
Степень R(x), очевидно, меньше (n - m), а потому в кодовом слове первые m, символов будут совпадать с информационными, а последние n - m символов будут проверочными.
В основу процедуры декодирования циклических кодов может быть положено свойство их делимости без остатка на порождающий полином Р(x).
В режиме обнаружения ошибок, если принятая последовательность делится без остатка на Р(x), делается вывод, что ошибки нет или она не обнаруживается. В противном случае комбинация бракуется.
В режиме исправления ошибок декодер вычисляет остаток R(x) от деления принятой последовательности F¢(x) на P(x). Этот остаток называют синдромом. Принятый полином F¢(x) представляет собой сумму по модулю два переданного слова F(x) и вектора ошибок Eош(x):
![]() .
.
Тогда синдром S(x) = F¢(x) mod P(x), так как по определению циклического кода F(x) mod P(x) = 0. Определенному синдрому S(x) может быть поставлен в соответствие определенный вектор ошибок Eош(x). Тогда переданное слово F(x) находят, складывая ![]() .
.
Однако один и тот же синдром может соответствовать 2m различным векторам ошибок. Положим, синдром S1(x) соответствует вектору ошибок E1(x). Но и все векторы ошибок, равные сумме E1(x) Å F(x), где F(x) любое кодовое слово, будут давать тот же синдром. Поэтому, поставив в соответствие синдрому S1(x) вектор ошибок E1(x), мы будем осуществлять правильное декодирование в случае, когда действительно вектор ошибок равен E1(x), во всех остальных 2m- 1 случаях декодирование будет ошибочным.
Для уменьшения вероятности ошибки декодирования из всех возможных векторов ошибок, дающих один и тот же синдром, следует выбирать в качестве исправляемого наиболее вероятный в заданном канале.
Например, для ДСК, в котором вероятность P0 ошибочного приёма двоичного символа много меньше вероятности (1 - P0) правильного приема, вероятность появления векторов ошибок уменьшается с увеличением их веса i. В этом случае следует исправлять в первую очередь вектор ошибок меньшего веса.
Если кодом могут быть исправлены только все векторы ошибок веса i и меньше, то любой вектор ошибки веса от i + 1 до n, будет приводить к ошибочному декодированию.
Вероятность ошибочного декодирования будет равна вероятности Pn(>i) появления векторов ошибок веса i + 1 и больше в заданном канале. Для ДСК эта вероятность будет равна
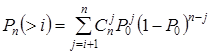 .
.
Общее число различных векторов ошибок, которые может исправлять циклический код, равно числу ненулевых синдромов – 2n-m - 1.
В курсовом проекте необходимо на основании вычисленного в предыдущем пункте значения k выбрать образующий полином по таблице приведенной в приложении А. По выбранному образующему полиному необходимо разработать схему кодера и декодера для случая обнаружения ошибки.
1.5 Показатели эффективности цифровой системы связи
Цифровые системы связи характеризуются качественными показателями, одним из которых является верности (правильность) передачи.
Для оценки эффективности системы связи вводят коэффициент использования канала связи за мощностью ![]() (энергетическая эффективность) и коэффициент использования канала по полосе частот
(энергетическая эффективность) и коэффициент использования канала по полосе частот ![]() (частотная эффективность):
(частотная эффективность):
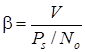 , (1.53)
, (1.53)
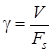 , (1.54)
, (1.54)
где V – скорость передачи информации;
![]() — отношения сигнал/шум на входе демодулятора
— отношения сигнал/шум на входе демодулятора
![]() ; (1.55)
; (1.55)
![]() - ширина полосы частот, которую занимает сигнал
- ширина полосы частот, которую занимает сигнал
![]() , (1.56)
, (1.56)
где М – число позиций сигнала.
Обобщенной характеристикой есть коэффициент использования канала по пропускной способности (информационная эффективность):
![]() . (1.57)
. (1.57)
Для непрерывного канала связи с учетом формулы Шеннона
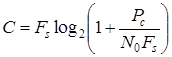
получаем следующее выражение
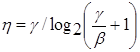 . (1.58)
. (1.58)
Соответственно теоремам Шеннона при h=1 можно получить зависимость между b и g:
b=g/(2g - 1), (1.59)
которая имеет название границы Шеннона, что отображает наилучший обмен между b и g в непрерывном канале. Эту зависимость удобно изобразить в виде кривой на плоскости b - g (рис.1.6).
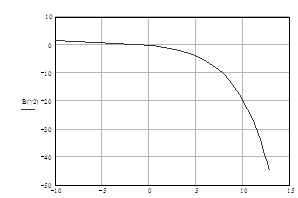
Рисунок 1.6 - Граница Шеннона
Эффективность системы может быть повышена за счет увеличения скорости передачи информации (повышать энтропию сообщений). Энтропия сообщений зависит от закона распределения вероятностей. Следовательно, для повышения эффективности необходимо осуществить перераспределение плотностей элементов сообщения.
Другие рефераты на тему «Коммуникации, связь и радиоэлектроника»:
Поиск рефератов
Последние рефераты раздела
- Микроконтроллер системы управления
- Разработка алгоритмического и программного обеспечения стандарта IEEE 1500 для тестирования гибкой автоматизированной системы в пакете кристаллов
- Разработка базы данных для информатизации деятельности предприятия малого бизнеса Delphi 7.0
- Разработка детектора высокочастотного излучения
- Разработка микропроцессорного устройства для проверки и диагностики двигателя внутреннего сгорания автомобиля
- Разработка микшерного пульта
- Математические основы теории систем