Методы математической статистики
X
DX1 DX2 . . . DXn
5. Метод наибольшего правдоподобия для нахождения оценок параметров плотности распределения
Метод наибольшего правдоподобия основывается на представлении выборки объема n как n-мерной случайной величине (Х1, Х2, ., Хn), где ![]() рассматриваются как независимые случайные величины с одинаков
рассматриваются как независимые случайные величины с одинаков
ой плотностью распределения f(x). Плотность распределения такой n-мерной случайной величины называется функцией правдоподобия L(x1, x2, ., xn), которая в силу независимости случайных величин ![]() равна произведению плотностей распределения случайных величин Х1, Х2, ., Хn:
равна произведению плотностей распределения случайных величин Х1, Х2, ., Хn:
L(x1, x2, ., xn) = f(x1) f(x2) . f(xn).
Отсюда следует, что всякую функцию у=у(x1, x2, ., xn) выборочных значений x1, x2, ., xn, называемую статистикой, можно представить как случайную величину, распределение которой однозначно определяется функцией правдоподобия.
Рассмотрим метод отыскания оценок параметров по опытным данным, который использует функцию правдоподобия.
Пусть f(x;а) – плотность распределения случайной величины Х (генеральной совокупности), зависящей от параметра а. Функция правдоподобия также будет зависеть от параметра а и иметь вид
![]()
Сущность метода наибольшего правдоподобия заключается в том, чтобы найти такое значение параметра а, при котором функция правдоподобия L(x1, x2, ., xn, а) была бы максимальной. Для этого необходимо решить уравнение
![]()
и найти то значение а, при котором функция L(x1, x2, ., xn, а) достигает максимума. С целью упрощения вычисления обычно максимизируют натуральный логарифм функции правдоподобия, пользуясь тем, что
![]()
Если неизвестными являются несколько параметров а1, а2, . , аm, то функция правдоподобия зависит от m переменных L = L(x1, x2, ., xn; а1, а2, . , аm) и решаются m уравнений
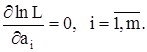
Пример. Пусть на вход приемного устройства поступает сумма двух сигналов: Y(t) = X + Z(t), где Х – неизвестный не зависящий от времени сигнал, а Z(t) – случайная помеха. В моменты времени t1, t2, . , tn производятся измерения величины Y(t). На основании опытных данных (выборки) y1 = y(t1), y2 = y(t2), . , yn=y(tn) нужно найти приближенное значение сигнала Х.
Решение. Пусть Z(t1), Z(t2), . , Z(tn) – независимые случайные величины распределены по нормальному закону с математическим ожиданием mZ = 0 и дисперсией D(Z) = s2. Тогда случайные величины ![]() также независимы, нормально распределены с неизвестным математическим ожиданием а и с той же дисперсией s2. Плотность распределения случайных величин Y(t1), Y(t2), . , Y(tn) имеет, таким образом, вид
также независимы, нормально распределены с неизвестным математическим ожиданием а и с той же дисперсией s2. Плотность распределения случайных величин Y(t1), Y(t2), . , Y(tn) имеет, таким образом, вид
![]()
Запишем функцию правдоподобия для n-мерной случайной величины (Y1, Y2, . , Yn):
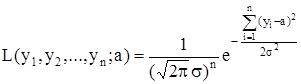
Tак как
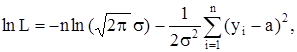
то из уравнения
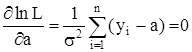
Имеем 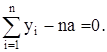
Значит
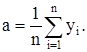
Нетрудно показать, что функция правдоподобия L = L(y1, y2, ., yn; а) при этом а достигает своего максимума. Таким образом мы показали, что оценка математического ожидания неизвестного сигнала Х по методу наибольшего правдоподобия в предположении нормального распределения аддитивной помехи является средним арифметическим измерений y1, y2, ., yn:
Метод наибольшего правдоподобия обладает важным свойством: он всегда приводит к состоятельным, хотя иногда и к смещенным, и эффективным оценкам.
На практике использование метода наибольшего правдоподобия часто приводит к необходимости решать достаточно сложные системы уравнений.
6. Метод наименьших квадратов
математическая статистика метод распределение выборка
Применим метод наибольшего правдоподобия для обработки экспериментальных данных. Предположим, что между физической величиной t (например, временем) и измеряемой y (сигналом) существует функциональная зависимость: y = j (t).
Вид этой зависимости необходимо определить из опыта. Положим, что в результате опыта мы получили ряд экспериментальных точек и построили график зависимости у от t. Экспериментальные точки всегда имеют ошибки измерения. Возникает вопрос, как по экспериментальным данным наилучшим образом воспроизвести зависимость у от t? Если провести интерполяционную кривую, то есть кривую, точно проходящую через экспериментальные точки, то это в силу ошибок измерения будет не самым лучшим решением. В случае, когда известна тенденция этой зависимости, другими словами вид кривой, то задача упрощается. Тогда возникает задача сглаживания - построение кривой таким образом, чтобы уклонение(в каком-то смысле) от экспериментальных точек кривой было минимальным.
Очень часто бывает так, что, зная вид кривой, из опыта требуется установить только некоторые параметры зависимости. Например, известно, что зависимость есть линейная y = at + b, а неизвестные величины а и b надлежит определить из экспериментальных данных y1= y(t1), y2= y(t2), . ,yn= y(tn). В общем случае функция у = j (t, a, b, .) может содержать много параметров (а,b, .). Требуется выбрать эти параметры так, чтобы кривая у = j (t, a, b, .) в каком-то смысле наилучшим образом отображала зависимость, полученную опытным путем. Для этого рассмотрим следующую модель.
Имеются наблюдения (экспериментальные данные) y1, y2, . ,yn точных величин j (t1, a, b, .) j (t2, a, b, .), . , j (tn, a, b, .). Тогда величина Di = yi - j (ti, a, b, .) ![]() является ошибкой наблюдения. Относительно ошибок будем полагать, что Di
является ошибкой наблюдения. Относительно ошибок будем полагать, что Di ![]() - независимые случайные величины с математическим ожиданием равным нулю (центрированные) и одинаковой дисперсией s2 подчинены нормальному закону распределения. Функция правдоподобия в этом случае будет иметь вид
- независимые случайные величины с математическим ожиданием равным нулю (центрированные) и одинаковой дисперсией s2 подчинены нормальному закону распределения. Функция правдоподобия в этом случае будет иметь вид
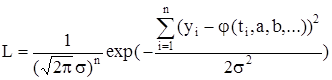
и достигает своего максимального значения путем выбора параметров а, b . лишь тогда, когда функция
![]()
достигнет минимального значения. Если измерения неравноценны, что эквивалентно наличию разных дисперсий si2 ошибок Di ![]() , то, исходя из функции правдоподобия, необходимо минимизировать функцию
, то, исходя из функции правдоподобия, необходимо минимизировать функцию
Другие рефераты на тему «Математика»:
Поиск рефератов
Последние рефераты раздела
- Анализ надёжности и резервирование технической системы
- Алгоритм решения Диофантовых уравнений
- Алгебраическое доказательство теоремы Пифагора
- Алгоритм муравья
- Векторная алгебра и аналитическая геометрия
- Зарождение и создание теории действительного числа
- Вероятностные процессы и математическая статистика в автоматизированных системах