Многомерный статистический анализ
Часто используют такой показатель качества алгоритма диагностики, как "вероятность правильной классификации" (при обработке конкретных данных - "частота правильной классификации"). Чуть ниже мы покажем, что этот показатель качества некорректен, а потому пользоваться им не рекомендуется. Целесообразно применять другой показатель качества алгоритма диагностики - оценку специал
ьного вида т.н. "расстояния Махаланобиса" между классами. Изложение проведем на примере разработки программного продукта для специалистов по диагностике материалов. Прообразом является диалоговая система «АРМ материаловеда», разработанная Институтом высоких статистических технологий и эконометрики для ВНИИ эластомерных материалов.
При построении информационно-исследовательской системы диагностики материалов (ИИСДМ) возникает задача сравнения прогностических правил «по силе». Прогностическое правило - это алгоритм, позволяющий по характеристикам материала прогнозировать его свойства. Если прогноз дихотомичен («есть» или «нет»), то правило является алгоритмом диагностики, при котором материал относится к одному из двух классов. Ясно, что случай нескольких классов может быть сведен к конечной последовательности выбора между двумя классами.
Прогностические правила могут быть извлечены из научно-технической литературы и практики. Каждое из них обычно формулируется в терминах небольшого числа признаков, но наборы признаков сильно меняются от правила к правилу. Поскольку в ИИСДМ должно фиксироваться лишь ограниченное число признаков, то возникает проблема их отбора. Естественно отбирать лишь те их них, которые входят в наборы, дающие наиболее «надежные» прогнозы. Для придания точного смысла термину «надежный» необходимо иметь способ сравнения алгоритмов диагностики по прогностической "силе".
Результаты обработки реальных данных с помощью некоторого алгоритма диагностики в рассматриваемом случае двух классов описываются долями: правильной диагностики в первом классе ![]() ; правильной диагностики во втором классе
; правильной диагностики во втором классе ![]() ; долями классов в объединенной совокупности
; долями классов в объединенной совокупности ![]()
Величины ![]() определяются ретроспективно.
определяются ретроспективно.
Нередко как показатель качества алгоритма диагностики (прогностической «силы») используют долю правильной диагностики
![]()
Однако показатель ![]() определяется, в частности, через характеристики
определяется, в частности, через характеристики ![]() и
и![]() частично заданные исследователем (например, на них влияет тактика отбора образцов для изучения). В аналогичной медицинской задаче величина
частично заданные исследователем (например, на них влияет тактика отбора образцов для изучения). В аналогичной медицинской задаче величина ![]() оказалась больше для тривиального прогноза (у всех больных течение заболевания будет благоприятно), чем для использованного в работе [13] группы под руководством академика АН СССР И.М. Гельфанда алгоритма выделения больных с прогнозируемым тяжелым течением заболевания, применение которого с медицинской точки зрения вполне оправдано. Другими словами, по доле правильной классификации алгоритм академика И.М. Гельфанда оказался хуже тривиального - объявить всех больных легкими, не требующими специального наблюдения. Этот вывод нелеп. И причина появления нелепости понятна. Хотя доля тяжелых больных невелика, но смертельные исходы сосредоточены именно в этой группе больных. Поэтому целесообразна гипердиагностика - рациональнее часть легких больных объявить тяжелыми, чем сделать ошибку в противоположную сторону. Применение теории статистических решений в рассматриваемой постановке вряд ли возможно, поскольку оценить количественно потери от смерти больного нельзя по этическим соображениям. Поэтому, на наш взгляд, долю правильной диагностики
оказалась больше для тривиального прогноза (у всех больных течение заболевания будет благоприятно), чем для использованного в работе [13] группы под руководством академика АН СССР И.М. Гельфанда алгоритма выделения больных с прогнозируемым тяжелым течением заболевания, применение которого с медицинской точки зрения вполне оправдано. Другими словами, по доле правильной классификации алгоритм академика И.М. Гельфанда оказался хуже тривиального - объявить всех больных легкими, не требующими специального наблюдения. Этот вывод нелеп. И причина появления нелепости понятна. Хотя доля тяжелых больных невелика, но смертельные исходы сосредоточены именно в этой группе больных. Поэтому целесообразна гипердиагностика - рациональнее часть легких больных объявить тяжелыми, чем сделать ошибку в противоположную сторону. Применение теории статистических решений в рассматриваемой постановке вряд ли возможно, поскольку оценить количественно потери от смерти больного нельзя по этическим соображениям. Поэтому, на наш взгляд, долю правильной диагностики ![]() нецелесообразно использовать как показатель качества алгоритма диагностики.
нецелесообразно использовать как показатель качества алгоритма диагностики.
Применение теории статистических решений требует знания потерь от ошибочной диагностики, а в большинстве научно-технических и экономических задач определить потери, как уже отмечалось, сложно. В частности, из-за необходимости оценивать человеческую жизнь в денежных единицах. По этическим соображениям это, на наш взгляд, недопустимо. Сказанное не означает отрицания пользы страхования, но, очевидно, страховые выплаты следует рассматривать лишь как способ первоначального смягчения потерь от утраты близких.
Для выявления информативного набора признаков целесообразно использовать метод пересчета на модель линейного дискриминантного анализа, согласно которому статистической оценкой прогностической "силы" является
![]()
где ![]() - функция стандартного нормального распределения вероятностей с математическим ожиданием 0 и дисперсией 1, а
- функция стандартного нормального распределения вероятностей с математическим ожиданием 0 и дисперсией 1, а ![]() - обратная ей функция.
- обратная ей функция.
Если классы описываются выборками из многомерных нормальных совокупностей с одинаковыми матрицами ковариаций, а для классификации применяется классический линейный дискриминантный анализ Р.Фишера, то величина ![]() представляет собой состоятельную статистическую оценку так называемого расстояния Махаланобиса между рассматриваемыми двумя совокупностями (конкретный вид этого расстояния сейчас не имеет значения), независимо от порогового значения, определяющего конкретное решающее правило. В общем случае показатель
представляет собой состоятельную статистическую оценку так называемого расстояния Махаланобиса между рассматриваемыми двумя совокупностями (конкретный вид этого расстояния сейчас не имеет значения), независимо от порогового значения, определяющего конкретное решающее правило. В общем случае показатель ![]() вводится как эвристический.
вводится как эвристический.
Пусть алгоритм классификации применяется к совокупности, состоящей из т объектов первого класса и n объектов второго класса.
Теорема 2. Пусть т, п®¥. Тогда для всех х
![]() ,
,
где ![]() - истинная "прогностическая сила" алгоритма диагностики;
- истинная "прогностическая сила" алгоритма диагностики; ![]() - ее эмпирическая оценка,
- ее эмпирическая оценка,
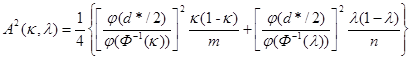 ;
;
![]() ) - плотность стандартного нормального распределения вероятностей с математическим ожиданием 0 и дисперсией 1.
) - плотность стандартного нормального распределения вероятностей с математическим ожиданием 0 и дисперсией 1.
С помощью теоремы 2 по ![]() и
и ![]() обычным образом определяют доверительные границы для "прогностической силы"
обычным образом определяют доверительные границы для "прогностической силы" ![]() .
.
Другие рефераты на тему «Экономико-математическое моделирование»:
Поиск рефератов
Последние рефераты раздела
- Выборочные исследования в эконометрике
- Временные характеристики и функция времени. Графическое представление частотных характеристик
- Автоматизированный априорный анализ статистической совокупности в среде MS Excel
- Биматричные игры. Поиск равновесных ситуаций
- Анализ рядов распределения
- Анализ состояния финансовых рынков на основе методов нелинейной динамики
- Безработица - основные определения и измерение. Потоки, запасы, утечки, инъекции в модели