Многомерный статистический анализ
Если исходные данные - матрица сходства ||d(x,y)||, то необходимо признать, что развитой вероятностно-статистической теории пока нет. Подходы к ее построению обсуждались в работе [8]. Одна из основных проблем - проверка "реальности" кластера, его объективного существования независимо от расчетов исследователя. Проблема "реальности" кластера давно обсуждается специалистами ра
зличных областей. Типичное рассуждение таково. Предположим, что результаты наблюдений можно рассматривать как выборку из некоторого распределения с монотонно убывающей плотностью при увеличении расстояния от некоторого центра. Примененный к подобным данным какой-либо алгоритм кластер-анализа порождает некоторое разбиение. Ясно, что оно - чисто формальное, поскольку выделенным таксонам (кластерам) не соответствуют никакие "реальные" классы. Другими словами, задача кластер-анализа не имеет решения, а алгоритм дает лишь группировку. При обработке реальных данных мы не знаем вида плотности. Проблема состоит в том, чтобы определить, каков результат работы алгоритма (реальные кластеры или формальные группы).
Частный случай этой проблемы - проверка обоснованности объединения двух кластеров, которые мы рассматриваем как два множества объектов, а именно, множества {a1, a2,…, ak} и {b1, b2,…, bm}. Пусть, например, используется алгоритм типа "Дендрограмма". Естественной представляется следующая идея. Пусть есть две совокупности мер близости: одна - меры близости между объектами, лежащими внутри одного кластера, т.е. d(ai,aj), 1<i<j<k, d(ba,bb), 1<a<b<m, и другая - меры близости между объектами, лежащими в разных кластерах, т.е. d(ai,ba), 1<i<k, 1<a<m. Эти две совокупности мер близости предлагается рассматривать как независимые выборки и проверять гипотезу о совпадении их функций распределения. Если гипотеза не отвергается, объединение кластеров считается обоснованным; в противном случае - объединять нельзя, алгоритм прекращает работу.
В рассматриваемом подходе есть две некорректности (см. также работу [8, разд.4]). Во-первых, меры близости не являются независимыми случайными величинами. Во-вторых, не учитывается, что объединяются не заранее фиксированные кластеры (с детерминированным составом), а полученные в результате работы некоторого алгоритма, и их состав (в частности, количество элементов) оказывается случайным От первой из этих некорректностей можно частично избавиться. Справедливо следующее утверждение.
Теорема 1. Пусть a1, a2,…, ak, b1, b2,…, bm - независимые одинаково распределенные случайные величины (со значениями в произвольном пространстве). Пусть случайная величина d(а1,а2) имеет все моменты. Тогда при k,т®¥ распределение статистики
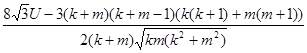
(где U - сумма рангов элементов первой выборки в объединенной выборке; первая выборка составлена из внутрикластерных расстояний (мер близости) d(ai,aj), 1<i<j<k, и d(ba,bb), 1<a<b<m, а вторая - из межкластерных расстояний d(ai,ba), 1<i<k, 1<a<m) сходится к стандартному нормальному распределению с математическим ожиданием 0 и дисперсией 1.
На основе теоремы 1 очевидным образом формулируется правило проверки обоснованности объединения двух кластеров. Другими словами, мы проверяем статистическую гипотезу, согласно которой объединение двух кластеров образует однородную совокупность. Если величина U слишком мала, статистическая гипотеза однородности отклоняется (на заданном уровне значимости), и возможность объединения отбрасывается. Таким образом, хотя расстояния между объектами в кластерах зависимы, но эта зависимость слаба, и доказана математическая теорема о допустимости применения критерия Вилкоксона для проверки возможности объединения кластеров.
О вычислительной сходимости алгоритмов кластер-анализа. Алгоритмы кластер-анализа и группировки зачастую являются итерационными. Например, формулируется правило улучшения решения задачи кластер-анализа шаг за шагом, но момент остановки вычислений не обсуждается. Примером является известный алгоритм "Форель", в котором постепенно улучшается положение центра кластера. В этом алгоритме на каждом шагу строится шар определенного заранее радиуса, выделяются элементы кластеризуемой совокупности, попадающие в этот шар, и новый центр кластера строится как центр тяжести выделенных элементов. При анализе алгоритма «Форель» возникает проблема: завершится ли процесс улучшения положения центра кластера через конечное число шагов или же он может быть бесконечным. Она получила название «проблема остановки». Для широкого класса так называемых "эталонных алгоритмов" проблема остановки была решена в работе [8]: процесс улучшения остановится через конечное число шагов.
Отметим, что алгоритмы кластер-анализа могут быть модифицированы разнообразными способами. Например, описывая алгоритм "Форель" в стиле статистики объектов нечисловой природы, заметим, что вычисление центра тяжести для совокупности многомерных точек – это нахождение эмпирического среднего для меры близости, равной квадрату евклидова расстояния. Если взять более естественную меру близости – само евклидово расстояние, то получим алгоритм кластер-анализа "Медиана", отличающийся от "Форели" тем, что новый центр строится не с помощью средних арифметических координат элементов, попавших в кластер, а с помощью медиан.
Проблема остановки возникает не только при построении диагностических классов. Она принципиально важна, в частности, и при оценивании параметров вероятностных распределений методом максимального правдоподобия. Обычно не представляет большого труда выписать систему уравнений максимального правдоподобия и предложить решать ее каким-либо численным методом. Однако когда остановиться, сколько итераций сделать, какая точность оценивания будет при этом достигнута? Общий ответ, видимо, невозможно найти, но обычно нет ответа и для конкретных семейств распределения вероятностей. Именно поэтому мы нет оснований рекомендовать решать системы уравнений максимального правдоподобия, вместо них целесообразно использовать т.н. одношаговые оценки (подробнее см. об этих оценках работу [12]). Эти оценки задаются конечными формулами, но асимптотически столь же хороши (на профессиональном языке - эффективны), как и оценки максимального правдоподобия.
О сравнении алгоритмов диагностики по результатам обработки реальных данных. Перейдем к этапу применения диагностических правил, когда классы, к одному из которых нужно отнести вновь поступающий объект, уже выделены.
В прикладных эконометрических исследованиях применяют различные методы дискриминантного анализа, основанные на вероятностно-статистических моделях, а также с ними не связанные, т.е. эвристические, использующие детерминированные методы анализа данных. Независимо от "происхождения", каждый подобный алгоритм должен быть исследован как на параметрических и непараметрических вероятностно-статистических моделях порождения данных, так и на различных массивах реальных данных. Цель исследования - выбор наилучшего алгоритма в определенной области применения, включение его в стандартные программные продукты, методические материалы, учебные программы и пособия. Но для этого надо уметь сравнивать алгоритмы по качеству. Как это делать?
Другие рефераты на тему «Экономико-математическое моделирование»:
Поиск рефератов
Последние рефераты раздела
- Выборочные исследования в эконометрике
- Временные характеристики и функция времени. Графическое представление частотных характеристик
- Автоматизированный априорный анализ статистической совокупности в среде MS Excel
- Биматричные игры. Поиск равновесных ситуаций
- Анализ рядов распределения
- Анализ состояния финансовых рынков на основе методов нелинейной динамики
- Безработица - основные определения и измерение. Потоки, запасы, утечки, инъекции в модели