Принятие решений
![]() . (2.26б)
. (2.26б)
В случае неизвестных параметров распределений ![]() находят их оптимальные оценки по обучающим выборкам (2.9):
находят их оптимальные оценки по обучающим выборкам (2.9):
![]() , (2.27а)
, (2.27а)
, (2.27б)
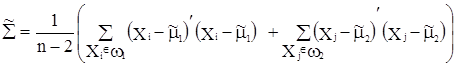 . (2.27в)
. (2.27в)
Оценка ковариационной матрицы ![]() в (2.27в) получена по двум обучающим выборкам (2.9). Оценки параметров в (2.27) используются в правилах классификации (2.26). Области наилучшей классификации определяются неравенствами
в (2.27в) получена по двум обучающим выборкам (2.9). Оценки параметров в (2.27) используются в правилах классификации (2.26). Области наилучшей классификации определяются неравенствами
![]() ,
,
![]() .
.
Формирование правил классификации для ![]() принципиально не отличаются от рассмотренной нами ситуации двух классов. Классификационные функции принимают вид
принципиально не отличаются от рассмотренной нами ситуации двух классов. Классификационные функции принимают вид
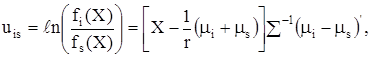 i, s = 1,2,…, k.
i, s = 1,2,…, k.
Области оптимальной классификации определяются из неравенств
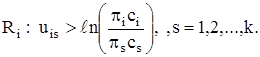
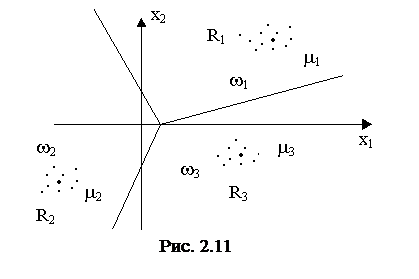
Классификационная функция ![]() связана с i-м и s-м классами. Так как каждая такая функция линейна, то область Ri ограничена гиперплоскостями (рис. 2.11).
связана с i-м и s-м классами. Так как каждая такая функция линейна, то область Ri ограничена гиперплоскостями (рис. 2.11).
Линейная дискриминантная функция (ЛДФ) широко используется в медицинской диагностике (МД). Сотни коллективов во всем мире работают над проблемой автоматизации МД. Испытаны различные математические методы, разные эвристические подходы, моделирующие деятельность врача. По ряду соображений наиболее перспективным методом в решении такой задачи является использование ЛДФ.
Для удобства в выражениях (2.26) введем обозначения:
![]() ,
, ![]()
Тогда неравенство (2.26) – правило классификации примет вид
![]() ,
,
где X=(x1, x2,…, xp) – симптомы, признаки отдельного пациента, W’ – коэффициенты, учитывающие диагностическую ценность признаков. Для исследуемого пациента Х имеем
![]() .
.
Чтобы отнести пациента Х к одному из классов w1 (рак) или к w2 (не рак) достаточно сравнить полученное значение (Х, W’) с пороговым значением ![]() и принять решение:
и принять решение:
CÎw1, если (C, W’)> a,
CÎw2, если (C, W’)£ a.
Значение параметров W, a вычисляются по картам обследования пациентов в поликлинике из класса w1 и класса w2.
2.7 Алгоритмы автоматической классификации (АК)
Синонимами термина «автоматическая классификация» будем считать следующие термины: «классификация без обучения, без учителя», «самообучение», «кластерный анализ», «таксономия».
Постановка задачи АК. Имеется множество n объектов
![]() , (2.28)
, (2.28)
каждый из которых описан p числовыми признаками
Xj=(xj1, xj2, …, xjp), p![]() 1, j = 1, 2,…, n.
1, j = 1, 2,…, n.
Множество (2.28) будем считать выборкой из некоторой генеральной совокупности. Требуется разделить множество X(n) на k классов (k < n) – непересекающихся подмножеств, каждое из которых состоит из элементов с похожими свойствами,
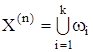 ,
,![]() , i, s
, i, s ![]() {1,2,…, k}.
{1,2,…, k}.
Выделение классов на множестве X(n) позволяет значительно сократить его описание без большой потери информации. Вместо перечисления всех объектов можно дать список k (k<n) «типичных» или «эталонных» представителей классов, перечислить номера (имена) объектов, входящих в состав каждого класса, их средние или максимальные отличия их свойств от свойств «эталонных». При небольшом числе классов описание данных становится обозримым и легко интерпретируемым.
Алгоритмы АК отличаются друг от друга процедурой группировки и критерием качества классификации. Классы могут иметь различную форму. Классы простой сферической формы можно выделить, пользуясь алгоритмами семейства FOREL, а классы более сложной (произвольной) формы – алгоритмами семейства KRAB, JOINT.
Алгоритмы этого семейства выделяют классы простой сферической формы. Число классов задается исследователем или выбирается автоматически. Для проведения классификации множества X(n) можно использовать евклидово расстояние между объектами. Объекты одного класса попадают в одну гиперсферу с определенным центром ![]() и заданным радиусом r0. Изменяя радиус r0, можно получить разное число классов k.
и заданным радиусом r0. Изменяя радиус r0, можно получить разное число классов k.
При фиксированном радиусе r0 алгоритм FOREL работает следующим образом. Выбирается произвольная точка Xj ![]() X(n), и в нее помещается центр
X(n), и в нее помещается центр ![]() гиперсферы S радиуса r0, S0(
гиперсферы S радиуса r0, S0(![]() , r0). Определяются внутренние точки гиперсферы:
, r0). Определяются внутренние точки гиперсферы:
![]() .
.
Вычисляется центр тяжести внутренних точек
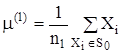 .
.
Строится новая гиперсфера радиуса r0 с центром в точке ![]() , S1(
, S1(![]() , r0). Находятся внутренние точки гиперсферы S1 и их центр тяжести
, r0). Находятся внутренние точки гиперсферы S1 и их центр тяжести
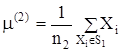 .
.
Процедура повторяется до тех пор, пока не перестанут изменяться координаты центра тяжести ![]() , т.е. до выполнения неравенства r(
, т.е. до выполнения неравенства r(![]() ,
,![]() )
)![]() , t = 1,2,…, e – заданное малое положительное число. При этом гиперсфера останавливается в области локального экстремума плотности точек множества X(n). Внутренние точки остановившейся гиперсферы St(m(t), r0) образуют класс w1, m1=m(t). Элементы класса w1 из дальнейшего рассмотрения исключаются.
, t = 1,2,…, e – заданное малое положительное число. При этом гиперсфера останавливается в области локального экстремума плотности точек множества X(n). Внутренние точки остановившейся гиперсферы St(m(t), r0) образуют класс w1, m1=m(t). Элементы класса w1 из дальнейшего рассмотрения исключаются.
Затем выбирается произвольная точка XiÎX(n) \ w1, iÎ{1, 2,…, n}, в нее помещается центр гиперсферы радиуса r0, и процедура выделения классов повторяется до тех пор, пока все множество X(n) не будет разделено на классы. Очевидно, количество полученных классов k тем больше, чем меньше радиус r0. Желательное для исследователя количество классов k может быть найдено соответствующим подбором радиуса r0.