Принятие решений
2.8 Предварительное обнаружение классов и оценивание их числа
Результаты классификации реальных объектов, проводимой при помощи математических методов и алгоритмов, зависят как от используемых методов, так и от пороговых значений параметров конкретного метода. При этом не исключено формальное разделение исследуемого множества объектов на группы, не являющиеся классами. Поэтому до пров
едения классификации необходимо знать, а имеет ли данное множество наблюдений классы или оно однородно (т.е. представляет собою один класс). Кроме того, полезно иметь такую информацию о структуре этого множества, как: степень удаленности классов друг от друга, их количество, их диаметры, центры тяжести классов, существование различия в плотностях точек классов и др. Получение такой информации намного упростит решение конкретной задачи классификации, например поможет выбрать оптимальный алгоритм классификации, точно задать пороговые значения, что сократит объем работ.
Такой предварительный анализ структуры данного множества проводится по гистограммам расстояний между всеми его точками. Исследование гистограмм данного множества наблюдений целесообразно изложить, начиная с одномерного случая.
Пусть множество Х(n) представляет собой одномерную выборку (р = 1):
![]() (2.32a)
(2.32a)
с плотностью вероятности ![]() . Упорядочив элементы множества Х(n) по возрастанию
. Упорядочив элементы множества Х(n) по возрастанию
![]() , (2.32б)
, (2.32б)
получим вариационный ряд (ВР). Значения x(1), x(n) отложим на числовой оси, отрезок [x(1), x(n)] разделим на t равных частей, t ³ 3 (рис. 2.15). Длина каждого полученного отрезка (xi, xi+1), i = 1, 2, …, t равна
![]() .
.
Пусть ni – число членов ВР (2.32б), попавших в i-й полуинтервал (xi, xi+1), i = 1, 2, …, t. Тогда оценка вероятности pi попадания в i-й полуинтервал случайной величины x равна
![]() . (2.33)
. (2.33)
Построим в каждом полуинтервале (xi, xi+1), прямоугольник с высотой hi и основанием D![]() такой, чтобы его площадь DSi,
такой, чтобы его площадь DSi,
![]() , (2.34)
, (2.34)
была равна ![]() в (2.33).
в (2.33).
![]() . (2.35)
. (2.35)
Из равенств (2.33) – (2.35) имеем
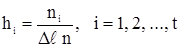 .
.
Так строится гистограмма ![]() плотности вероятности f(x) данных наблюдений, один из видов которой представлен на рис. 2.15. Отметим, что последним из полученных интервалов гистограммы должен быть отрезок [xt, xt+1], xt+1 = x(n), x1 = x(1).
плотности вероятности f(x) данных наблюдений, один из видов которой представлен на рис. 2.15. Отметим, что последним из полученных интервалов гистограммы должен быть отрезок [xt, xt+1], xt+1 = x(n), x1 = x(1).
Число интервалов, на которые делится отрезок [x(1), x(n)], задается исследователем. Эти интервалы могут быть разной длины.
 |
При увеличении объема наблюдений n и уменьшении длины интервала D![]() гистограмма
гистограмма ![]() стремится к функции
стремится к функции ![]() ,
,
![]() .
.
Если исследуемое множество (2.32) состоит из классов, далеко отстоящих друг от друга (рис. 2.16), то его гистограмма имеет достаточно глубокий локальный минимум (ЛМ), изображенный на рис. 2.17.
Пусть ЛМ наблюдается в промежутке [xq, xq+1]. Фиксируются два ближайших к нему максимума, из которых выделяется наименьший, наблюдаемый в промежутке (xu, xu+1). Далее исследуется (xq, xu+1) полуинтервал.
Определение 2.1. ЛМ гистограммы называется статистически значимым (СЗЛМ), если на отрезке [xq, xu+1] отвергается гипотеза H0 о равномерном распределении подвыборки множества (2.32), принадлежащей полуинтервалу (xq, xu+1). H0: f(x) = f0(x),
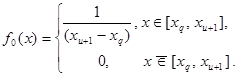
Определение 2.2. ЛМ гистограммы называется статистически незначимым, если на отрезке [xq, xu+1] принимается гипотеза H0 о равномерном распределении подвыборки множества (2.32), принадлежащей (xq, xu+1).
Проверка гипотезы Н0 проводится с использованием известных статистических критериев c2, w2, Вилкоксона, знаков и др.
Если гистограмма исследуемого множества имеет хотя бы один СЗЛМ, то это множество содержит классы, далеко отстоящие друг от друга. Число классов k оценивается по числу СЗЛМ гистограммы ![]() :
: ![]() .
.
Число далеко удаленных друг от друга классов определяется равенством ![]() .
.
За границы классов принимаются середины тех отрезков гистограммы, в которых наблюдается ее СЗЛМ. На рис. 2.17 точка x* – граница классов w1, w2.
Если гистограмма исследуемого множества наблюдений не имеет ЛМ или все ее ЛМ статистически незначимы (рис. 2.18), то это множество однородно, т.е. представляет собою один класс, или содержит классы, недалеко отстоящие друг от друга.
Если число признаков p каждого объекта данного множества наблюдений (2.28) p ³ 2, то предварительную информацию о наличии классов, их числе, степени их удаленности друг от друга и др. можно получить, по крайней мере, тремя способами.
1. Построение и анализ гистограммы каждого признака xs, s = 1, 2, …, p. Каждая такая гистограмма может дать оценку снизу для числа классов k, ![]() , ms – число СЗЛМ гистограммы s-го признака. Тогда имеем
, ms – число СЗЛМ гистограммы s-го признака. Тогда имеем ![]() .
.
2. Построение и анализ многомерных гистограмм. Строятся t p-мерных интервалов, t = t1t2…tp, ts – число интервалов, на которое разбиваются значения s-го признака, s = 1, 2, …, p. Подсчитывается число точек множества (2.28), попавших в каждый p-мерный интервал ni, i = 1, 2, …, t. Затем выделяются интервалы, содержащие наибольшее число точек, по правилу ni ³ n0, n0 – некоторое заданное пороговое значение. Вычисляются центры тяжести таких интервалов, эти интервалы объединяются в один класс по расстоянию между их центрами по правилу «ближний к ближнему». Кроме того, фиксируются интервалы, содержащие наименьшее число точек, ![]() ,
, ![]() – другое пороговое значение. По таким интервалам проводятся границы между классами. Интервалы, для элементов которых имеет место неравенство
– другое пороговое значение. По таким интервалам проводятся границы между классами. Интервалы, для элементов которых имеет место неравенство ![]() , объединяются с интервалами с наибольшим содержанием точек по правилу «ближний к ближнему». Предварительный анализ многомерных интервалов – очень трудоемкий процесс, практически не осуществимый при больших значениях n и p.
, объединяются с интервалами с наибольшим содержанием точек по правилу «ближний к ближнему». Предварительный анализ многомерных интервалов – очень трудоемкий процесс, практически не осуществимый при больших значениях n и p.