Разработка программы-компилятора
рис.5, б
рис.5. Результаты тестирования программы, не содержащей ошибок.
Текст программы содержит ошибочные лексемы var% и $+MN.
program var15;
var% n: integer;
begin
n: =$+MN;
repeat
n: =n- (-XII);
until n<$-0A;
end.
Результат - в таблицу кодов лексем эти лексемы занесены с типом Е, что означает, что они ошибочны (см. Рис.6, а, б), программа выдал
а также сообщения об ошибках (Рис.6, в).
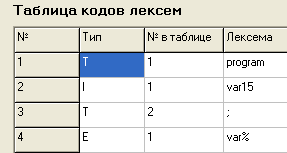
Рис.6, а
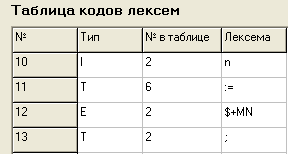
Рис.6, б
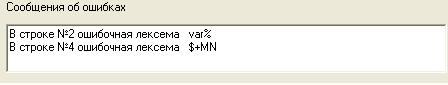
Рис.6, в
Рис.6. Результаты тестирования программы, содержащей ошибочные лексемы.
3. Разработка синтаксического анализатора
3.1 Уточнение грамматики языка применительно к варианту задания
Синтаксический анализ производится методом рекурсивного спуска.
Анализатор, основанный на этом методе, состоит из отдельных процедур для распознавания нетерминальных символов, определённых в грамматике. Каждая такая процедура ищет во входном потоке лексем подстроку, которой может быть поставлен в соответствие нетерминальный символ, распознаваемый с помощью данной процедуры. В процессе своей работы процедура может обратиться к другим подобным процедурам для поиска других нетерминальных символов. Если эта процедура интерпретирует входную подстроку как соответствующий нетерминальный символ, то она заканчивает свою работу, передаёт в вызвавшую её программу или процедуру признак успешного завершения и устанавливает указатель текущей лексемы на первую лексему после распознанной подстроки. Если же процедура не может найти подстроку, которая могла бы быть интерпретирована как требуемый нетерминальный символ, она заканчивается с признаком неудачного завершения и выдает соответствующее диагностическое сообщение.
Правила синтаксического анализа относятся к грамматике вида LL (1), т.е. используется левосторонний просмотр и левосторонний вывод, при этом необходимо просматривать не более 1 символа.
Множество правил грамматики реализуемого языка, записанных в форме Бэкуса-Наура, имеет следующий вид:
1. <программа>→program<имя программы>;
var<список описаний>
begin<список операторов>end.
2. <имя программы>→ИМЯ
3. <список описаний>→<описание>; {<описание>; }
4. <описание>→<список имён>: <тип>
5. <тип>→real
6. <список имён>→ИМЯ{, ИМЯ}
7. <список операторов>→<оператор>; {<оператор>; }
8. <оператор>→<присваивание> | <цикл>
9. <присваивание>→ИМЯ: =<выражение>
10. <выражение>→<простое выражение>{ (=, <, <>, >, >=, <=) <простое выражение>}
11. <простое выражение>→<терм>{+<терм> | - <терм>}
12. <терм>→<множитель>{*<множитель> |/<множитель>}
13. <множитель>→ИМЯ | КОНСТАНТА | <простое выражение>
14. <цикл>→repeat<тело цикла>until<выражение>
15. <тело цикла>→<оператор>|<составной оператор>
16. <составной оператор>→begin<список операторов>end
В грамматике, помимо общепринятых, используются следующие терминальные символы: ИМЯ - идентификатор; КОНСТАНТА - 16-ричная или римская константа.
3.2 Разработка алгоритма синтаксического анализа
Синтаксический анализ производится методом рекурсивного спуска. Синтаксический анализатор представляет собой набор функций, каждая из которых должна распознавать отдельный нетерминальный символ грамматики. При этом разработка проходит от общего к частному. Первой строится функция распознавания начального символа грамматики, потом функции, непосредственно вызываемые из нее и так далее.
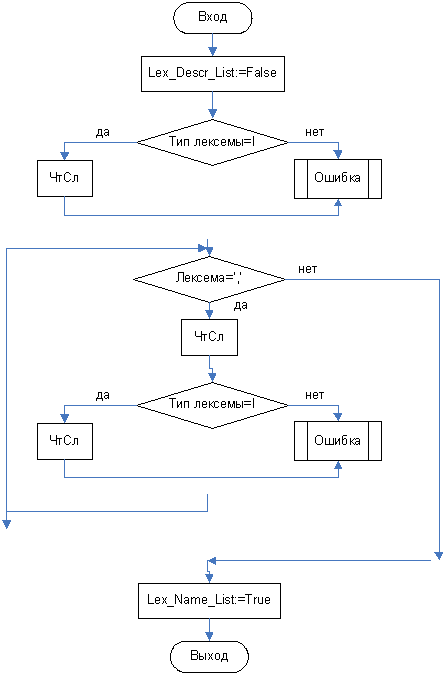
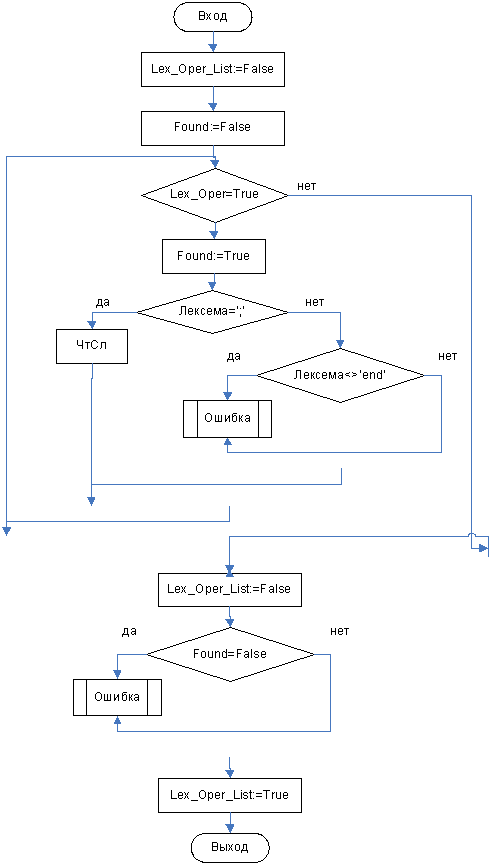
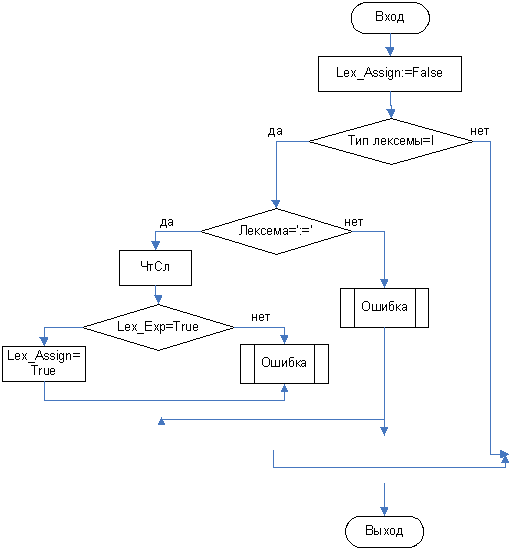
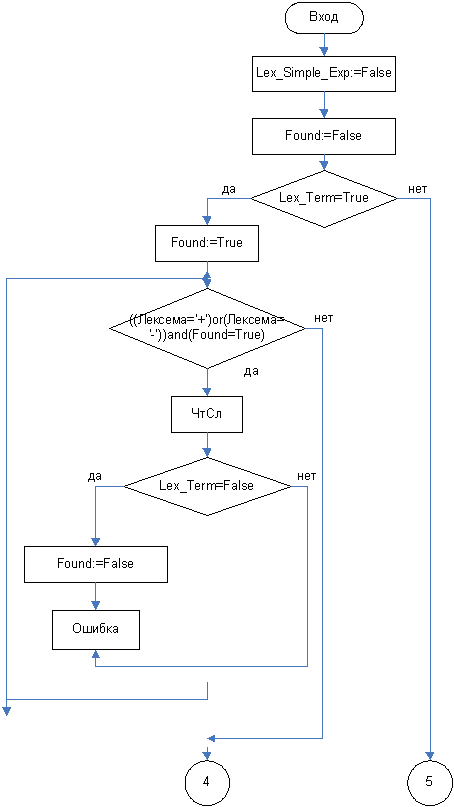
Далее рассматриваются алгоритмы отдельных функций распознавания. Общий метод их построения заключается в следующем: изначально значение функции устанавливается в FALSE. Далее происходит поиск символов входящих в распознаваемый нетерминал. Если правило содержит другой нетерминальный символ, то происходит вызов соответствующей функции. Если же необходимо проверить наличие терминального символа, то функция сама выполняет запрос на чтение следующей лексемы и сравнивает ее с той, которая должна присутствовать в конструкции. Чтение следующей лексемы состоит в выборе следующего элемента из таблицы кодов лексем, т.е. в увеличении номера текущего элемента на 1 (в блок-схеме будет обозначаться как ЧтСл). Если происходит ошибка, то выполнение функции прекращается с вызовом процедуры вывода сообщения об ошибке (в блок-схеме будет обозначаться как Ошибка). Причем при выполнении анализа такое сообщение выдается один раз, иначе следующие сообщения могут иметь недостоверную информацию. Сообщение содержит номер строки и описание обнаруженной ошибки. Если ошибок не обнаружено, то в конце работы функции ее результат становится TRUE.
Lex_Progr: <программа>
Lex_Progr_Name: <имя программы>
Lex_Descr_List: <список описаний>
Lex_Descr: <описание>
Lex_Name_List: <список имён>
Lex_Type: <тип>
Lex_Oper_List: <список операторов>
Lex_Oper: <оператор>
Lex_Assign: <присваивание>
Lex_Exp: <выражение>
Lex_Simple_Exp: <простое выражение>
Lex_Term: <терм>
Lex_Mnozh <множитель>
Lex_Repeat_Intil: <цикл>
Lex_Body <тело цикла>
3.3 Алгоритмы распознающих функций
Ниже представлены упрощённые блок-схемы функций распознавания. Простые функции, такие, как распознавание оператора или имени программы, не рассматриваем в силу их очевидности.
3.3.1 Функция Lex_Progr
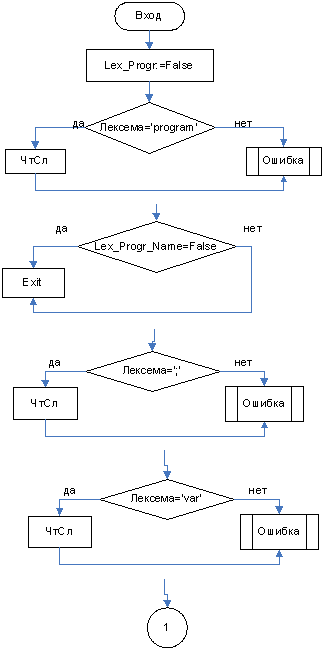
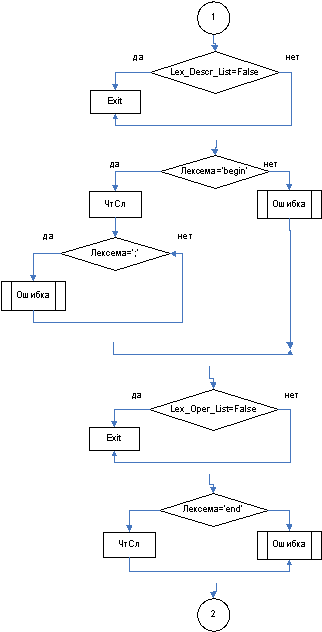
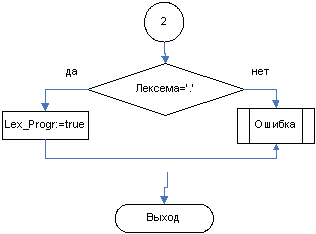
3.3.2 Функция Lex_Descr_List
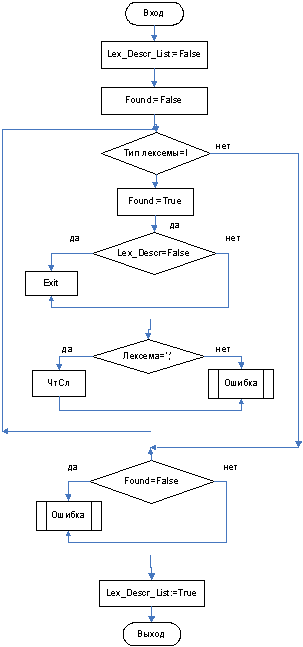
3.3.3 Функция Lex_Descr
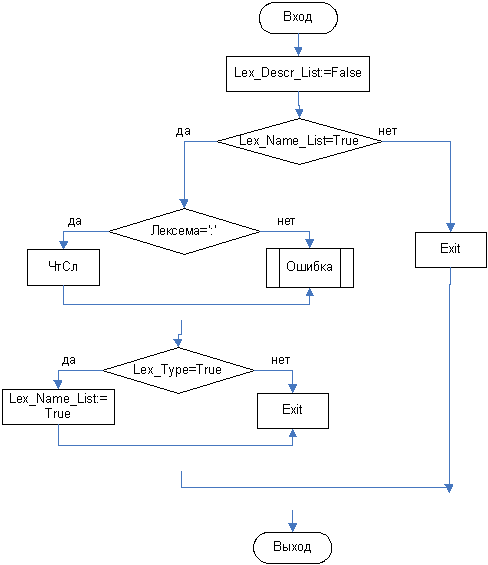
3.3.4 Функция Lex_Name_List
3.3.5 Функция Lex_Oper_List
3.3.6 Функция Lex_Assign
3.3.7 Функция Lex_Exp
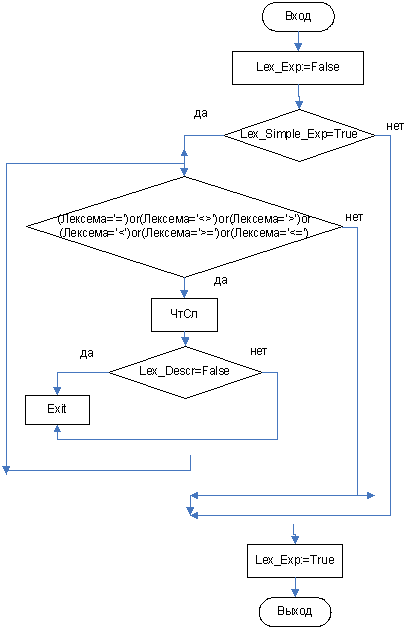
3.3.8 Функция Lex_Simple_Exp
Другие рефераты на тему «Программирование, компьютеры и кибернетика»:
Поиск рефератов
Последние рефераты раздела
- Основные этапы объектно-ориентированного проектирования
- Основные структуры языка Java
- Основные принципы разработки графического пользовательского интерфейса
- Основы дискретной математики
- Программное обеспечение системы принятия решений адаптивного робота
- Программное обеспечение
- Проблемы сохранности информации в процессе предпринимательской деятельности