Разработка программы-компилятора
Дерево вывода состоит из начального (корневого) узла. В него включают еще промежуточные узлы и внешние узлы.
Каждой ветви соответствует одно из правил грамматики.
Входные данные - таблица кодов лексем, сформированная на стадии лексического анализа.
Выходные данные - сообщение об успешном завершении анализа или сообщение об имеющихся ошибках.
2. Разработка лексического анализ
атора
2.1 Выбор и обоснование структур данных
1. Таблица констант организована в виде двоичных деревьев
Для хранения таблицы имен используется массив из записей Const_tab, содержащих следующие элементы:
Номер лексемы.
Лексема.
Тип константы (16-ричная или римская).
Ширина константы.
10-тичная форма.
Левая ветвь дерева (номер элемента, который является левой ветвью для данного).
Правая ветвь дерева (номер элемента, который является правой ветвью для данного).
Путь к элементу по дереву (последовательность левых и правых ветвей, которые необходимо пройти, чтобы достичь данного элемента).
2. Таблица терминальных символов организована в виде двоичных деревьев
Для хранения таблицы имен используется массив из записей Term_tab, содержащих следующие элементы:
Номер лексемы.
Лексема.
Разделитель (если лексема является разделителем, то это поле равно 1, если нет, то 0).
Знак операция (если лексема является знаком операции, то это поле равно 1, если нет, то 0).
Ключевое слово (если лексема является ключевым словом, то это поле равно 1, если нет, то 0)
Левая ветвь дерева (номер элемента, который является левой ветвью для данного).
Правая ветвь дерева (номер элемента, который является правой ветвью для данного).
Путь к элементу по дереву (последовательность левых и правых ветвей, которые необходимо пройти, чтобы достичь данного элемента).
3. Для хранения таблицы идентификаторов используется метод с использованием хэш-функций
Для хранения таблицы констант используется массив из записей Id_tab, содержащих следующие элементы:
Ссылка на элемент цепочки.
Номер.
Лексема.
В данном случае хэш-функция вычисляется по методу деления, т.е.
h (k): = {K/α}
где K - ключ записи, α - некоторый коэффициент
Для наиболее удобного распределения данных в таблице коэффициент α примем:
α= Li+2
где L - количество символов i-той строки, в которой хранится идентификатор.
Код K рассчитывается как сумма ASCII-кодов символов строки, в которой хранится идентификатор.
4. Для хранения таблицы кодов лексем используется массив из записей Code_tab, содержащих следующие элементы:
Номер.
Тип лексемы (C - константа, I - идентификатор, T - терминальный символ).
Номер в таблице констант, идентификаторов или терминальных символов.
Лексема.
Номер в таблице кодов лексем.
Для организации поиска используется последовательный метод.
2.2 Разработка автоматных грамматик для распознавания лексем
Автоматными или регулярными грамматиками называются грамматики, продукции которых имеют одну из двух форм:
|
Праволинейная |
Леволинейная |
|
A→aB |
A→Ba |
|
A→a |
A→a |
где a Î Т; А, В Î N
Эти грамматики широко используются для построения лексических анализаторов. Грамматику лексических единиц обычно явно не описывают, а строят эквивалентный ей граф распознавания лексических единиц.
Грамматика для идентификаторов:
<имя>→<буква>{<буква>|<цифра>’_’}
<буква>→ (’a’. ’z’)
<цифра>→ (‘0’. ’9’)
Грамматика для констант:
<константа>→<16-рич. константа>|<римск. константа>
Для 16-ричных констант:
<16-рич. константа>→ (‘$+’,’$-‘) (<цифра>, ‘A’. ’F’) { (<цифра>,‘A’. ’F’) }
Для римских констант:
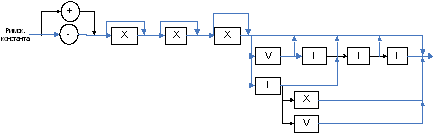
2.3 Разработка автоматов, работающих по правилам грамматики
2.3.1 Автомат для распознавания имён
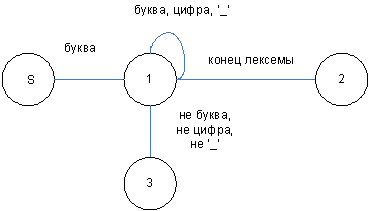
рис.1. Автомат для распознавания имён
Состояния автомата:
S - начальное состояние;
1 - промежуточное состояние, соответствующее продолжению формирования имени;
2 - конечное состояние, соответствующее выделению правильного идентификатора;
3 - конечное состояние, соответствующее ошибке при выделении идентификатора.
2.3.2 Автомат для распознавания 16-ричных констант
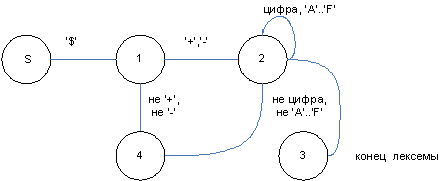
рис.3. Автомат для распознавания 16-ричных констант
Состояния автомата:
S - начальное состояние;
1 - промежуточное состояние, обозначающее, что распознан символ начала константы ‘$’;
2 - промежуточное состояние, обозначающее, что распознан знак константы, и продолжение формирования константы;
3 - конечное состояние, соответствующее выделению правильной 16-ричной константы;
4 - конечное состояние, соответствующее ошибке при выделении 16-ричной константы.
2.3.3 Автомат для распознавания римских констант
Римские константы образуются по следующим правилам:
Римская система нумерации состоит из семи знаков: I - 1, V - 5, X - 10, C - 100, D - 500, M - 1000. В данной работе используются только три первых знака, т.е. автомат может распознавать числа от 1 (I) до 39 (XXXIX).
Если меньший знак пишется после большего, то его прибавляют к большему числу; если же перед большим - вычитают. Вычитать можно только числа, начинающиеся с 1, в данном случае - 1, т.к не имеет смысла вычитать, например, 5 из 5 (в результате 0) или из 10 (в результате 5).
Знаки, эквивалентные числам, начинающимся с 1 (1, 10, 100, 1000), могут использоваться от одного до 3 раз. Знаки, эквивалентные числам, начинающимся с 5 (5, 50, 500) могут использоваться только 1 раз. Таким образом, чтобы образовать число 4, нужно из 5 вычесть 1 (IV), а чтобы образовать число 6, нужно прибавить 1 к 5 (VI).
В соответствии с приведёнными правилами, сформируем ряд ограничений для автомата-распознавателя:
Символ X может встречаться в начале строки от 1 до 3 раз подряд (см. правило 3).
Символ V может встречаться не более 1 раза в начале строки и после 1 или более символов X (см. правило 3).
Символ I может встречаться от 1 до 3 раз подряд в начале строки, а также в конце правильной строки, образованной символами X и V (см. ограничения 1 и 2, правило 3).
Символ X может встречаться в конце строки 1 раз после символа I, если перед последним находятся только символы X или ничего (иначе будет нарушено правило 2 - неизвестно, к какому символу будет относиться символ I).
Другие рефераты на тему «Программирование, компьютеры и кибернетика»:
Поиск рефератов
Последние рефераты раздела
- Основные этапы объектно-ориентированного проектирования
- Основные структуры языка Java
- Основные принципы разработки графического пользовательского интерфейса
- Основы дискретной математики
- Программное обеспечение системы принятия решений адаптивного робота
- Программное обеспечение
- Проблемы сохранности информации в процессе предпринимательской деятельности