Процесс обработки статистикой информации
Таким образом:
S1=10040,86/1=10040,86
S2=93010,09/28=3321,79
Для установления соответствия эмпирической регрессии линейной форме связи определяют дисперсионное отношение F=S1/S2 и сравнивают со значением из справочника при заданной надежности.
F=10040,86/3321,79=3,03, табличное значение F=4,2.
Фактическое значение меньше табличного, значит прямолинейная форма связи не соот
ветствует эмпирическим данным.

Рисунок 2 - Графическая интерпретация теоретической и эмпирической регрессии
Корреляционный анализ статистических данных показал относительно высокую степень связи между факторным и результативным признаками.
Регрессионный анализ позволил подобрать регрессионную линейную модель методом наименьших квадратов. Насколько эта модель адекватна экспериментальным данным доказала проверка с помощью дисперсионного анализа. В частности, была проверена гипотеза о том, что регрессионная модель точнее описывает результаты эксперимента, чем среднее по всем опытам. С достоверностью 95 % эта гипотеза подтвердилась.
Задача № 6
Для изучения показателей производительности труда на предприятии, число рабочих на котором составляет 5000 человек, было проведено методом случайного бесповторного отбора обследование квалификации рабочих в процентном отношении (таблица 10).
Таблица 10
|
Число рабочих |
Квалификация рабочих (тарифные разряды) |
Заданная вероятность Р | |||||
|
1 |
2 |
3 |
4 |
5 |
6 | ||
|
180 |
5 |
9 |
47 |
50 |
42 |
27 |
0,996 |
С заданной вероятностью следует определить:
а) процентное соотношение выборки для проведения обследования;
б) величину средней ошибки выборки;
в) предельную ошибку выборочной сpeднeй;
г) пределы, в которых находится средний тарифный разряд рабочих предприятия.
Средняя ошибка выборки для средней показывает расхождение выборочной и генеральной средней. При случайном бесповторном отборе она рассчитывается по следующей формуле
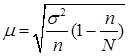 , (8)
, (8)
где µ-средняя ошибка выборочной вредней;
n - численность выборки;
N - численность генеральной совокупности;
σ2 - дисперсия выборочной совокупности.
Предельная ошибка выборки рассчитывается по следующей формуле
∆=µ*t, (9)
где ∆ - предельная ошибка выборки;
µ - средняя ошибка выборочной средней;
t =2,9 - коэффициент доверия, зависящий от значения вероятности (р).
Пределы, в которых находится данная выборочная средняя, определяются по следующей формуле
![]() , (10)
, (10)
где ![]() числовые значения пределов;
числовые значения пределов;
![]() - среднее значение выборочной совокупности;
- среднее значение выборочной совокупности;
∆ - предельная ошибка выборки.
Определим процентное соотношение выборки
Для этого количество рабочих каждого разряда разделим на количество всех рабочих и умножим на 100%.
Для удобства составим таблицу по результатам расчета
Таблица 11 - Результаты обработки исходных данных
|
Тарифный разряд |
I |
II |
III |
IV |
V |
VI |
|
Число рабочих |
5 |
9 |
47 |
50 |
42 |
27 |
|
Процентное соотношение |
2,78 |
5,0 |
26,11 |
27,78 |
23,33 |
15,0 |
|
Заданная вероятность разряда, р |
0,028 |
0,05 |
0,26 |
0,277 |
0,231 |
0,15 |
Для нахождения величины средней ошибки выборки необходимо определить величину дисперсии.
Способ I - Для этого найдем математическое ожидание
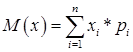 , (11)
, (11)
где х - число рабочих разряда;
р - заданная вероятность разряда
![]()
Далее, дисперсия равна
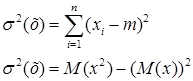 (12)
(12)
![]()
Таким образом, средняя ошибка выборки
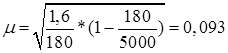
Предельная ошибка выборки
![]()
Средний тарифный разряд рабочих предприятия равен 3,5.
Предел нахождения выборочной средней
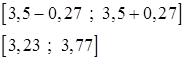
Способ II - Определим дисперсию:
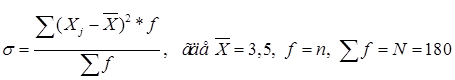
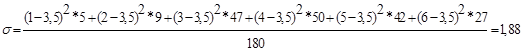
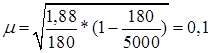
Предельная ошибка выборки
![]()
Предел нахождения выборочной средней
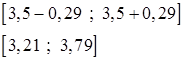
Оба способами дали практически одинаковый результат, что говорит о верности расчетов.
Задача № 7
Сведения об объемах вывозки древесины по 10 леспромхозам представлены в таблице 11.
Таблица 11
|
Леспромхоз |
Годы | |||||||||
|
1976 |
1977 |
1978 |
1979 |
1980 |
1981 |
1982 |
1983 |
1984 |
1985 | |
|
Объем вывозки древесины, тыс. м3 | ||||||||||
|
2 |
169 |
172 |
183 |
189 |
198 |
212 |
235 |
249 |
268 |
301 |
Другие рефераты на тему «Экономико-математическое моделирование»:
Поиск рефератов
Последние рефераты раздела
- Выборочные исследования в эконометрике
- Временные характеристики и функция времени. Графическое представление частотных характеристик
- Автоматизированный априорный анализ статистической совокупности в среде MS Excel
- Биматричные игры. Поиск равновесных ситуаций
- Анализ рядов распределения
- Анализ состояния финансовых рынков на основе методов нелинейной динамики
- Безработица - основные определения и измерение. Потоки, запасы, утечки, инъекции в модели