Выборочные исследования в эконометрике
Пусть объем выборки равен n. Тогда ответы опрашиваемых можно представить как X1 , X2 ,…,Xn , где Xi = 1, если i-й респондент выбрал первую подсказку, и Xi = 0, если i-й респондент выбрал вторую подсказку, i=1,2,…,n. В вероятностной модели предполагается, что случайные величины X1 , X2 ,…,Xn независимы и одинаково распределены. Поскольку эти случайные величины принимают два значения, то ситуация
описывается одним параметром р - долей выбирающих первую подсказку во всей генеральной совокупности. Тогда
Р(Xi = 1) = р, Р(Xi = 0)= 1-р, i=1,2,…,n.
Пусть m = X1 + X2 +…+Xn . Оценкой вероятности р является частота р*=m/n. При этом математическое ожидание М(р*) и дисперсия D(p*) имеют вид
М(р*) = р, D(p*)= p(1-p)/n.
По Закону Больших Чисел (ЗБЧ) теории вероятностей (в данном случае - про теореме Бернулли) частота р* сходится (т.е. безгранично приближается) к вероятности р при росте объема выборки. Это и означает, что оценивание проводится тем точнее, чем больше объем выборки. Точность оценивания можно указать. Займемся этим.
По теореме Муавра-Лапласа теории вероятностей
![]()
где ![]() - функция стандартного нормального распределения с математическим ожиданием 0 и дисперсией 1,
- функция стандартного нормального распределения с математическим ожиданием 0 и дисперсией 1,
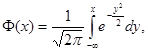
где ![]() = 3,1415925…-отношение длины окружности к ее диаметру, e= 2,718281828… - основание натуральных логарифмов. График плотности стандартного нормального распределения
= 3,1415925…-отношение длины окружности к ее диаметру, e= 2,718281828… - основание натуральных логарифмов. График плотности стандартного нормального распределения
![]()
очень точно изображен на германской денежной банкноте в 10 немецких марок. Эта банкнота посвящена великому немецкому математику Карлу Гауссу (1777-1855), среди основных работ которого есть относящиеся к нормальному распределению. В настоящее время нет необходимости вычислять функцию стандартного нормального распределения и ее плотность по приведенным выше формулам, поскольку давно составлены подробные таблицы (см., например, [3]), а распространенные программные продукты содержат алгоритмы нахождения этих функций.
С помощью теоремы Муавра-Лапласа могут быть построены доверительные интервалы для неизвестной эконометрику вероятности. Сначала заметим, что из этой теоремы непосредственно следует, что
![]()
Поскольку функция стандартного нормального распределения симметрична относительно 0, т.е. ![]() то
то ![]()
Зададим доверительную вероятность ![]() . Пусть
. Пусть ![]() удовлетворяет условию
удовлетворяет условию
![]()
т.е.
![]()
Из последнего предельного соотношения следует, что
![]()
Следовательно, нижняя доверительная граница имеет вид
![]()
в то время как верхняя доверительная граница такова:
![]()
Наиболее распространенным (в прикладных исследованиях) значением доверительной вероятности является ![]() Иногда употребляют термин "95% доверительный интервал". Тогда
Иногда употребляют термин "95% доверительный интервал". Тогда ![]()
Пример. Пусть n=500, m=200. Тогда p* =0,40. Найдем доверительный интервал для ![]()
![]()
Таким образом, хотя в достаточно большой выборке 40% респондентов говорят "да", можно утверждать лишь, что во всей генеральной совокупности таких от 35,7% до 44,3% - крайние значения отличаются на 8,6%.
Замечание. С достаточной для практики точностью можно заменить 1,96 на 2.
Удобные для использования в практической работе маркетолога и социолога таблицы точности оценивания разработаны во ВЦИОМ (Всероссийском центре по изучению общественного мнения). Приведем здесь несколько модифицированный вариант одной из них.
Табл.5. Допустимая величина ошибки выборки (в процентах)
|
Объем группы Доля р* |
1000 |
750 |
600 |
400 |
200 |
100 |
|
Около 10% или 90% |
2 |
3 |
3 |
4 |
5 |
7 |
|
Около 20% или 80% |
3 |
4 |
4 |
5 |
7 |
9 |
|
Около 30% или 70% |
4 |
4 |
4 |
6 |
9 |
10 |
|
Около 40% или 60% |
4 |
4 |
5 |
6 |
8 |
11 |
|
Около 50% |
4 |
4 |
5 |
6 |
8 |
11 |
В условиях рассмотренного выше примера надо взять вторую снизу строку. Объема выборки 500 нет в таблице, но есть объемы 400 и 600, которым соответствуют ошибки в 6% и 5% соответственно. Следовательно, в условиях примера целесообразно оценить ошибку как ((5+6)/2)% = 5,5%. Эта величина несколько больше, чем рассчитанная выше (4,3%). С чем связано это различие? Дело в том, что таблица ВЦИОМ связана не с доверительной вероятностью ![]() а с доверительной вероятностью
а с доверительной вероятностью ![]() которой соответствует множитель
которой соответствует множитель ![]() Расчет ошибки по приведенным выше формулам дает 5,65%, что практически совпадает со значением, найденным по табл.5.
Расчет ошибки по приведенным выше формулам дает 5,65%, что практически совпадает со значением, найденным по табл.5.
Другие рефераты на тему «Экономико-математическое моделирование»:
Поиск рефератов
Последние рефераты раздела
- Выборочные исследования в эконометрике
- Временные характеристики и функция времени. Графическое представление частотных характеристик
- Автоматизированный априорный анализ статистической совокупности в среде MS Excel
- Биматричные игры. Поиск равновесных ситуаций
- Анализ рядов распределения
- Анализ состояния финансовых рынков на основе методов нелинейной динамики
- Безработица - основные определения и измерение. Потоки, запасы, утечки, инъекции в модели