Основы дискретной математики

Рисунок 1.1 – Массив
Двоичный поиск – очень мощный метод. Если, например, длина массива равна 1023, после первого сравнения область сужается до 511 элементов, а после второй – до 255. Легко посчитать, что для поиска в массиве из 1023 элементов достаточно 10 сравнений.
Кроме поиска нам необходимо бывает вставлять и у
далять элементы. К сожалению, массив плохо приспособлен для выполнения этих операций. Например, чтобы вставить число 18 в массив на рисунке 1.1, нам понадобится сдвинуть элементы A[3]… A[6] вниз – лишь после этого мы сможем записать число 18 в элемент A[3]. Аналогичная проблема возникает при удалении элементов. Для повышения эффективности операций вставки / удаления предложены связанные списки.
Иначе двоичный поиск (бинарный поиск) называют поиском делением пополам. В большинстве случаев процедура поиска применяется к упорядоченным данным (телефонный справочник, библиотечные каталоги и пр.).
Односвязные списки
На рисунке 1.2 те же числа, что и раньше, хранятся в виде связанного списка; слово «связанный» часто опускают. Предполагая, что X и P являются указателями, число 18 можно вставить в такой список следующим образом:
X->Next = P->Next;
P->Next = X;
Списки позволяют осуществить вставку и удаление очень эффективно. Поинтересуемся, однако, как найти место, куда мы будем вставлять новый элемент, т. е. каким образом присвоить нужное значение указателю P. Увы, для поиска нужной точки придется пройтись по элементам списка. Таким образом, переход к спискам позволяет уменьшить время вставки / удаления элемента за счет увеличения времени поиска.
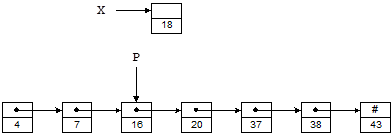
Рисунок 1. 2 – Односвязный список
Поиск в бинарных деревьях
Мы использовали двоичный поиск для поиска данных в массиве. Этот метод чрезвычайно эффективен, поскольку каждая итерация вдвое уменьшает число элементов, среди которых нам нужно продолжать поиск. Однако операции вставки и удаления элементов не столь эффективны. Двоичные деревья позволяют сохранить эффективность всех трех операций – если работа идет со «случайными» данными. В этом случае время поиска оценивается как O (lg n). Наихудший случай – когда вставляются упорядоченные данные. В этом случае оценка время поиска – O(n).
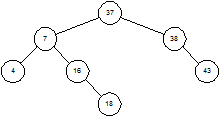
Двоичное дерево – это дерево, у которого каждый узел имеет не более двух наследников. Пример бинарного дерева приведен на рисунке 1.5. Предполагая, что Key содержит значение, хранимое в данном узле, мы можем сказать, что бинарное дерево обладает следующим свойством: у всех узлов, расположенных слева от данного узла, значение соответствующего поля меньше, чем Key, у всех узлов, расположенных справа от него, – больше. Вершину дерева называют его корнем. Узлы, у которых отсутствуют оба наследника, называются листьями. Корень дерева на рисунке 1.3 содержит число 20, а листья – 4, 16, 37 и 43. Высота дерева – это длина наидлиннейшего из путей от корня к листьям. В нашем примере высота дерева равна 2.
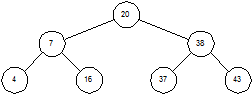
Рисунок 1.3 – Двоичное дерево
Чтобы найти в дереве какое-то значение, мы стартуем из корня и движемся вниз. Например, для поиска числа 16, мы замечаем, что 16 < 20, и потому идем влево. При втором сравнении имеем 16 > 7, так что мы движемся вправо. Третья попытка успешна – мы находим элемент с ключом, равным 16.
Каждое сравнение вдвое уменьшает количество оставшихся элементов. В этом отношении алгоритм похож на двоичный поиск в массиве. Однако, все это верно только в случаях, когда наше дерево сбалансировано. На рисунке 1.4 показано другое дерево, содержащее те же элементы. Несмотря на то, что это дерево тоже бинарное, поиск в нем похож, скорее, на поиск в односвязном списке, время поиска увеличивается пропорционально числу запоминаемых элементов.
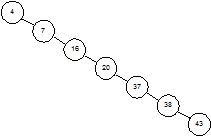
Рисунок 1.4 – Несбалансированное бинарное дерево
Вставка и удаление
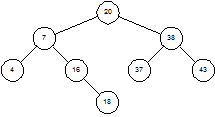
Чтобы лучше понять, как дерево становится несбалансированным, посмотрим на процесс вставки пристальнее. Чтобы вставить 18 в дерево на рисунке 1.3 мы ищем это число. Поиск приводит нас в узел 16, где благополучно завершается. Поскольку 18 > 16, мы попросту добавляет узел 18 в качестве правого потомка узла 16 (рисунок 1.5).
Теперь мы видим, как возникает несбалансированность дерева. Если данные поступают в возрастающем порядке, каждый новый узел добавляется справа от последнего вставленного. Это приводит к одному длинному списку. Обратите внимание: чем более «случайны» поступающие данные, тем более сбалансированным получается дерево.
Удаления производятся примерно так же – необходимо только позаботиться о сохранении структуры дерева. Например, если из дерева на рисунке 1.5 удаляется узел 20, его сначала нужно заменить на узел 37. Это даст дерево, изображенное на рисунок 1.6. Рассуждения здесь примерно следующие. Нам нужно найти потомка узла 20, справа от которого расположены узлы с большими значениями. Таким образом, нам нужно выбрать узел с наименьшим значением, расположенный справа от узла 20. Чтобы найти его, нам и нужно сначала спуститься на шаг вправо (попадаем в узел 38), а затем на шаг влево (узел 37); эти двухшаговые спуски продолжаются, пока мы не придем в концевой узел, лист дерева.
|
Рисунок 1.5 – Бинарное дерево после добавления узла 18 |
Рисунок 1.6 – Бинарное дерево после удаления узла 20 |
Разделенные списки
Разделенные списки – это связные списки, которые позволяют вам прыгнуть (skip) к нужному элементу. Это позволяет преодолеть ограничения последовательного поиска, являющегося основным источником неэффективного поиска в списках. В то же время вставка и удаление остаются сравнительно эффективными. Оценка среднего времени поиска в таких списках есть O (lg n). Для наихудшего случая оценкой является O(n), но худший случай крайне маловероятен.
Идея, лежащая в основе разделенных списков, очень напоминает метод, используемый при поиске имен в адресной книжке. Чтобы найти имя, вы помечаете буквой страницу, откуда начинаются имена, начинающиеся с этой буквы. На рисунке 1.6, например, самый верхний список представляет обычный односвязный список. Добавив один «уровень» ссылок, мы ускорим поиск. Сначала мы пойдем по ссылкам уровня 1, затем, когда дойдем до нужного отрезка списка, пойдем по ссылкам нулевого уровня.
Эта простая идея может быть расширена – мы можем добавить нужное число уровней. Внизу на рисунке 1.6 мы видим второй уровень, который позволяет двигаться еще быстрее первого. При поиске элемента мы двигаемся по этому уровню, пока не дойдем до нужного отрезка списка. Затем мы еще уменьшаем интервал неопределенности, двигаясь по ссылкам 1‑го уровня. Лишь после этого мы проходим по ссылкам 0‑го уровня.
Другие рефераты на тему «Программирование, компьютеры и кибернетика»:
Поиск рефератов
Последние рефераты раздела
- Основные этапы объектно-ориентированного проектирования
- Основные структуры языка Java
- Основные принципы разработки графического пользовательского интерфейса
- Основы дискретной математики
- Программное обеспечение системы принятия решений адаптивного робота
- Программное обеспечение
- Проблемы сохранности информации в процессе предпринимательской деятельности