Автоматизация работы с базами данных
Таким образом, понятно, что из тела программы можно вызвать любую подпрограмму, кроме Delt и Search, так как они локальны – определены внутри других подпрограмм, и существуют только при их работе. Связь по вызовам подпрограмм представлена на рис. 2.
5.2 Описание алгоритма решения задачи
Алгоритм – это метод (способ) решения задачи, записанный по определенным правилам, обеспечивающим одн
означность его понимания и механического исполнения при всех значениях исходных данных (из некоторого множества значений). В толковом словаре дано общепринятое определение этого понятия: алгоритм – точное предписание, определяющее процесс, ведущий от варьируемых начальных данных к искомому результату.
Решаемая задача является достаточно сложной. В ходе разработки программы проводилась ее декомпозиция – задача разбивалась на подзадачи, которые в свою очередь также имеют достаточно сложные алгоритмы решения. Описание данных алгоритмов может быть весьма большим по объему. Поэтому имеет смысл рассмотреть укрупненные схемы алгоритмов программы и подпрограмм, отражающих суть без излишних подробностей, с пояснениями, описывающими определенные сложные моменты при необходимости.
На рис. 4 представлена блок-схема алгоритма программы. В блоках описанные выполняемые на данном этапе действия. Естественно, что в ходе разработке программы они, скорее всего, будут выделены в подпрограммы.
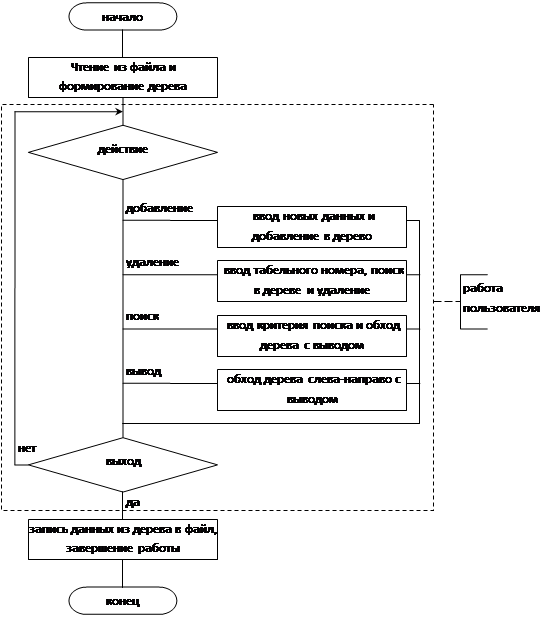
Рис. 4. Укрупненная схема алгоритма программы
Первый этап – чтение из файла и формирование дерева явно реализуется не сложно: чтение по-компонентно из типизированного файла, добавление считанных данных о работнике в дерево. Процесс повторяется пока не конец файла. Вследствие простоты реализации нет смысла приводить алгоритм. Алгоритм добавления в дерево будет рассмотрен далее.
Второй этап – организация работы пользователя. Пользователь выбирает действие: добавление работника, удаление работника, поиск и вывод всего списка работников. Все операции осуществляются с уже сформированной динамической структурой – деревом, работа с файлом не производится.
При выборе действия «добавление» пользователь вводит данные о добавляемом работнике, далее осуществляется добавление данного работника в дерево. Словесный алгоритм добавления работника в двоичное дерево поиска рассмотрен в разделе «4. Сведения о методе решения». Данный алгоритм подразумевает использование рекурсии. Вследствие того, что алгоритм описывают стандартную операцию для дерева поиска, и рассматривается в любой литературе по динамическим структурам данных, нет смысла приводить описание в виде блок-схемы. Реализующая алгоритм процедура подробно прокомментирована в тексте программы. По этим же причинам не рассматриваются блок-схемы алгоритмов удаления, поиска и обхода двоичного дерева поиска.
При выборе действия «удаление» пользователь вводит табельный номер удаляемого работника. Далее осуществляется поиск по дереву в случае нахождение работника, осуществляется его удаление из дерева поиска, словесный алгоритм которого рассмотрен в разделе «4. Сведения о методе решения».
При выборе действия «поиск» пользователь выбирает критерий поиска: по фамилии, должности или табельному номеру. Затем осуществляется обход дерева слева-направо (словесный алгоритм приведен в разделе «4. Сведения о методе решения») и осуществляется вывод работников, попадающих под условия критерия поиска.
При выборе действия «вывод» осуществляется обход дерева слева-направо с выводом каждого работника.
Третий этап – запись результатов работы в файл. В ходе данного этапа осуществляется обход дерева сверху-вниз с последовательной записью компоненты структуры в типизированный файл.
5.3 Описание входных и выходных данных программы
Назначение программы – введение простой базы данных. Данные при запуске программы читаются из файла Rab.dat. Также после окончания работы программы они записываются в данный файл. Для возможности отмены сохраненных в файл последних изменений ведется копия перезаписываемого файла Rab.tmp.
Чтение данных осуществляется в динамическую структуру – двоичное дерево поиска, в которой они в ходе выполнения программы и обрабатываются. В процессе работы программы данные могут добавляться пользователем посредством ввода с клавиатуры и удалятся из динамической структуры.
Файл Rab.dat представляет собой с точки зрения Turbo Pascal типизированный файл. Компоненты данного файла представляют собой запись, содержащую информацию о работнике. Структура компоненты типизированного файла описана в виде пользовательского типа-записи в пользовательском модуле Trees, следовательно, данный тип является глобальным, и имеет следующую структуру:
CompF = record
fio : string[40];
num : word;
pol : char;
dat : string[10];
dol : string[40]
end;
Описание полей записи в порядке следования:
- fio – фамилия имя отчество работника;
- num – табельный номер (положительное целое число);
- pol – пол работника (символ «м» или «ж»);
- dat – дата рождения (предполагается запись формата – ДД.ММ.ГГГГГ);
- dol – должность;
Указанные поля берутся исходя из условия поставленного задания. Тип полей выбирался исходя из допустимых значений для хранимых данных. Табельный номер является уникальным номером для каждого работника, поэтому нет смысла вводить порядкового номера или других уникально идентифицирующих работника полей. Тем более построение динамической структуры – двоичного дерево поиска по условию задачи осуществляется на основании ключевого поля – номера зачетки.
Также для проведения анализа работы программы, распределения памяти и хранения данных необходимо оценить размер хранимой информации о каждом работнике, то есть знать размер отдельной компоненты типизированного файла или, что то же самое, знать размер типа записи. Такую информацию можно определить стандартной функцией SizeOf (упоминалась выше): SizeOf(CompF) = 103 Бт.
Данный размер складывается исходя из необходимых размеров для полей. Необходимо помнить, что реально для хранение строк выделяется на 1 байт больше (string[40] – 41 Бт).
Таким образом, можно утверждать, что если в файл записана информация о 100 работниках, то размер файла будет равен: 100 х 103 Бт = 10300 Бт.
Так обработка данных осуществляется в динамической структуре – двоичном дереве поиска, необходимо рассмотреть компоненту этой структуры. Компонента дерева представляет собой запись, содержащую информацию о работнике с аналогичной структурой, что и компонента типизированного файла. Данное правило соблюдалось исходя из соображений об использовании процедуры копирования участка памяти Move (упоминалась выше по тексту). Это происходит в случае чтения из файла и размещения этих данных в дереве. Присваивание по полям занимает и больше места по тексту в программе и выполняется медленнее, чем операция копирования участка памяти. Структура компоненты дерева следующая:
pTree = ^Tree;
Tree = record
Другие рефераты на тему «Программирование, компьютеры и кибернетика»:
Поиск рефератов
Последние рефераты раздела
- Основные этапы объектно-ориентированного проектирования
- Основные структуры языка Java
- Основные принципы разработки графического пользовательского интерфейса
- Основы дискретной математики
- Программное обеспечение системы принятия решений адаптивного робота
- Программное обеспечение
- Проблемы сохранности информации в процессе предпринимательской деятельности