Адекватный компьютерный перевод научно-популярного текста
Поиск и добавление
До тех пор, пока память переводов была линейной, сегменты неделимыми, а сравнение строгим, решение задачи поиска сводилось к введению отношения строгого лексикографического порядка над множеством сегментов на исходном языке. Иными словами, определялся оператор "меньше", на основе которого можно было осуществить обыкновенный двоичный поиск, и проверку на р
авенство. С введением оператора "нечеткого совпадения", который позволял оценить степень сходства для любых двух сегментов, решение проблемы поиска резко усложнилось и, без дополнительных ухищрений с различного рода индексацией, стало эквивалентно задаче полного перебора. Предложенная многоуровневая модель памяти переводов, собственно, и предоставляет некоторый механизм неявной индексации: каждое входящее в сегмент слово, по сути, идентифицирует некоторое подмножество ориентированного графа памяти переводов, состоящее из узлов, которые можно достичь, начав обход от узла, соответствующего выбранному слову.
Используя особенности выбранной структуры памяти переводов, задачу поиска сегментов, похожих на заданный, можно решить путем выполнения следующих действий (рис. 4):
1. разбить заданный сегмент на слова;
2. найти в памяти переводов все узлы, соответствующие этим словам;
3. спускаясь по графу отношений наследования, помещать в список найденных сегментов все встречаемые узлы.
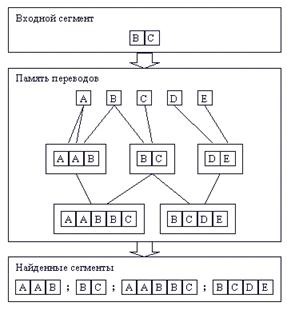
Рис. 4
Резонным представляется вопрос о том, в каком порядке следует предоставлять найденные сегменты переводчику: ведь приведенная процедура поиска выберет из памяти все сегменты, пересекающиеся с заданным по крайней мере по одному слову. Каковы правила фильтрации и сортировки найденных сегментов?
Ответ на этот вопрос лежит за пределами выбранного формализма, однако в этом нет ничего страшного. Дело в том, что результат поиска представляет собой классический вариант одноуровневой памяти переводов, анализ которого может быть произведена методами, формализованными в рамках существующих сред перевода. Для обеспечения эффективности поиска целесообразно осуществлять оценку "пригодности" сегментов по мере их нахождения. Например, если некоторый сегмент полностью совпадает с эталоном, то все его потомки в графе могут быть автоматически исключены из поиска.
Теперь поговорим о задаче добавления нового сегмента в память переводов. Очевидным условием корректности процедуры добавления является обеспечение успешного поиска. Стало быть, добавляемый сегмент должен иметь в числе своих предков (не обязательно прямых) все составляющие его слова. Следуя целям оптимальности, можно заключить, что среди предков должны присутствовать также узлы графа, содержащие фрагменты данного сегмента. Иными словами, если в памяти переводов присутствуют сегменты "AB" и "CD", то сегмент "ABCD" должен стать наследником этих двух сегментов. Аналогично, если в памяти присутствует сегмент "ABCD", то добавляемый сегмент "AB" должен стать его предком. В общем случае при добавлении сегмента в граф памяти переводов могут существовать альтернативные варианты наследования. В такой ситуации схема добавления заметно усложнится. В любом случае, проблема построения оптимальной иерархии классов решается в рамках объектно-ориентированного подхода, поэтому мы не будем заострять здесь на ней внимание.
Долгое время системы машинного перевода и памяти переводов представляли два конкурирующих направления и никогда не рассматривались вместе кроме как в противопоставлении. На сегодняшний день взгляды меняются, и хотя фирмы не придают своим ноу-хау широкой огласки, заметна тенденция к совместному использованию в некоторых системах обеих технологий. Предлагаемая модель демонстрирует один из возможных вариантов такой интеграции. Более того, она представляет собой попытку показать, что под машинный перевод и память переводов можно подвести общую основу, и создать такую систему профессионального перевода, в которой оба механизма действуют как единое целое.
ГЛАВА 2. Ошибки, возникающие в процессе компьютерного перевода текстов научно-технического характера. Искажения, неточности, неясности
При компьютерном возникает ряд типичных ошибок. Интересен тот факт, что текст получаемый при помощи разных электронных переводчиков так же различается.
2.1 Типология ошибок
Классификация ошибок, появляющихся как результат некорректного компьютерного перевода и передачи исходного текста, весьма проста- специфика и степень воздействия ошибки на адресата перевода.
Искажение существенно дезинформирует адресата относительно предметно-логического и прагматического значения в исходном тексте.
Неточности так же как и искажения, дезинформируют адресата перевода относительно предмета высказывания. Однако степень дезинформации менее существенна, чем в случае искажения.
При оценке ущерба для двуязычной коммуникации в результате неверной передачи исходного содержания следует, разумеется, иметь ввиду и жанр переводимого текста, и прежде всего подразделение текстов на те, в которых изложены факты, и те что построены на артефактах (художественном вымысле). Порой то, что в первом случае было искажением, во втором можно отнести к неточности.
Неясность отличается от искажения и неточности тем, что оказывает на адресата не столько дезинформирующее, сколько дезориентирующее воздействие: если в первых двух случаях мысль адресата, можно условно сказать, направляется не в ту сторону, то в случае неясности она порой просто как ты топчется на месте, не зная, какое направление избрать, поскольку содержание изложено переводчиком таким образом, что непонятно «куда мысли идти».
Как показывает практика, причиной недочетов в части передачи исходного содержания может быть не только непонимание или недостаточное понимание этого текста программой , но и просто неудачный подбор переводческого соответствия.
2.2 Сравнительный анализ
В качестве примера хотелось бы привести перевод статьи из журнала «Deutschland» сделанной при помощи переводчика PROMT 7 Giant.
Исходный текст:
Peking
Zentrale des chinesischen Staatsvernsehens und TV-Kulturzentrum.
Es ist der Werk, das an die Grenzen der Architektur geht und die natürlichen Gesetze der Schwerkraft offensichtlich ignoriert: das neue Gebäude des chinesischen Staatsvernsehens CCTV. In Pekings Geschäftsviertel ragen die beiden L-förmigen Türme schräg in die Höhe- eine unglaubliche Statik. Die Türme scheinen fast umzufallen, am Ende werden sie über 200 Meter hoch sein. Verantwortlich für dieses aufregende Bauprojekt, eines der größten weltweit, ist der deutsche Architekt Ole Scheeren. Der 36-Järige ist Partner im Office for Metropolitan Architekture (OMA) des niederländischen Stararchitekten Rem Koolhaas Ole Scheeren kümmert sich um das Asiengeschäft des Architektenbüros und leitet in Peking seit fünf Jahren ein Team von 60 Architekten und 120 Ingenieuren. Im CCTV-Neubau aus Glas und Stahl werden später einmal 10000 Menschen arbeiten, seine Nutzfläche beträgt gigantische 540000 Quadratmeter. Im Jahr 2009 soll die neue Fernsehzentrale fertig sein. Im angrenzenden TV-Kulturzentrum(TVCC) werden bereits während der olympischen Spiele 2008 Fernsehsender aus aller Welt untergebracht. Für Ole Scheeren gibt es derzeit kein vergleichbares Bauobjekt: „Das statische System des CCTV wäre wahrscheinlich vor fünf bis zehn Jahren nicht zu realisieren gewesen, weil die Computer-Software nicht weit genug entwickelt waren.
Другие рефераты на тему «Иностранные языки и языкознание»:
Поиск рефератов
Последние рефераты раздела
- Важнейшие требования к композиции документа
- Гармония речи и основные законы современной риторики
- Выразительность речи и ее условия
- Времена группы Simple
- Версия унификации и усовершенствования азерлийских национальных фамилий в Азербайджане
- Грамматика английского языка в примерах и упражнениях
- Грамматические правила русского языка