Проектирование компилятора
Можно написать функцию, отражающую функционирование любого детерминированного КА. Чтобы запрограммировать такую функцию, достаточно иметь переменную, которая бы отображала текущее состояние КА, а переходы из одного состояния в другое на основе символов входной цепочки могут быть построены с помощью операторов выбора. Работа функции должна продолжаться до тех пор, пока не будет достигнут конец в
ходной цепочки. Для вычисления результата функции необходимо по ее завершении проанализировать состояние КА. Если это одно из конечных состояний, то функция выполнена успешно и входная цепочка принимается, если нет, то входная цепочка не принадлежит заданному языку.
Однако в общем случае задача лексического анализатора шире, чем просто проверка цепочки символов лексемы на соответствие ее входному языку. Он должен правильно определить конец лексемы (об этом было сказано выше) и выполнить те или иные действия по запоминанию распознанной лексемы (занесение ее в таблицу лексем). Набор выполняемых действий определяется реализацией компилятора. Обычно эти действия выполняются сразу же при обнаружении конца распознаваемой лексемы.
Во входном тексте лексемы не ограничены специальными символами. Определение границ лексем — это выделение тех строк в общем потоке входных символов, для которых надо выполнять распознавание. Если границы лексем всегда определяются (а выше было принято именно такое соглашение), то их можно определить по заданным терминальным символам и по символам начала следующей лексемы. Терминальные символы - это пробелы, знаки операций, символы комментариев, а также разделители (запятые, точки е запятой и др.). Набор таких терминальных символов может варьироваться в зависимости от входного языка. Важно отметить, что знаки операций сами также являются лексемами и необходимо не пропустить их при распознавании текста.
Таким образом, алгоритм работы простейшего сканера можно описать так:
□ просматривается входной поток символов программы на исходном языке до обнаружения очередного символа, ограничивающего лексему;
□ для выбранной части входного потока выполняется функция распознавания лексемы;
□ при успешном распознавании информация о выделенной лексеме заносится в таблицу лексем, и алгоритм возвращается к первому этапу;
□ при неуспешном распознавании выдается сообщение об ошибке, а дальнейшие действия зависят от реализации сканера: либо его выполнение прекращается, либо делается попытка распознать следующую лексему (идет возврат к первому этапу алгоритма).
Работа программы-сканера продолжается до тех пор, пока не будут просмотрены все символы программы на исходном языке из входного потока.
Заключение
В результате выполнения курсовой работы для заданного входного языка были построены отдельные части компилятора.
В первой части работы была разработана программа, которая получает на входе набор идентификаторов, организует таблицу идентификаторов методом упорядоченного списка и методом простого рехэширования с помощью произведения, позволяет осуществить многократный поиск идентификатора в этих таблицах.
Во второй части работы была написана программа, которая выполняет лексический анализ входного текста и порождает таблицу лексем с указанием их типов и значений.
Отдельные части компилятора, разработанные в данной курсовой работе, дают представление о технике и методах, лежащих в основе построения компиляторов.
Список использованной литературы
1. Кампапиец Р.II. Манькоп Е.В., Филатов Н.Е. Системное программирование. Основы построения трансляторов: Учеб. пособие для высших и средних учебных заведений. – СПб.: КОРОНА Принт, 2000. – 256 с.
2. Системное программное обеспечение: Учебник для вузов/ А.Ю. Молчанов- СПб.: Питер, 2003.- 396 с.
3. http://trubetskoy1.narod.ru/index.html
Приложение 1
Задание:
Организовать таблицу идентификатором с помощью простого рехеширования с помощью произведения.
Кодпрограммы:
unit Unit1;
interface
uses
Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms,
Dialogs, ComCtrls, StdCtrls, ExtCtrls, Grids;
type
TForm1 = class(TForm)
OpenDialog1: TOpenDialog;
Panel1: TPanel;
GroupBox1: TGroupBox;
Button1: TButton;
Memo2: TMemo;
Button2: TButton;
Edit1: TEdit;
GroupBox2: TGroupBox;
StringGrid1: TStringGrid;
Label1: TLabel;
procedure Button1Click(Sender: TObject);
procedure FormCreate(Sender: TObject);
procedure Button2Click(Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
end;
const
hash_min=Ord('0')+Ord('0')+Ord('0');
HASH_MAX= Ord('z')+Ord('z')+Ord('z');
REHASH1 = 127;
REHASH2 =223;
var
Form1: TForm1;
lengtM:integer;
sName:string ;
Find,NumSTR:integer;
implementation
function VarHash(const sName:string):longint;
var
i:integer;
begin
for i:=1 to length(sname) do
begin
Result:=(Ord(sName[i])+Ord(sName[(Length(sName)+i) div 2]) * i{HASH_MIN}) mod (HASH_MAX - HASH_MIN+i) + HASH_MiN;
if Result < HASH_MIN then Result := HASH_MIN;
end;
end;
{$R *.dfm}
procedure TForm1.Button1Click(Sender: TObject);
var
fName,str:string;
i:integer;
begin
form1.OpenDialog1.Execute;
fname:=form1.OpenDialog1.FileName;
form1.Memo2.Lines.loadfromfile(fName);
form1.StringGrid1.RowCount:=memo2.Lines.Count+1;
NumSTR:=memo2.Lines.Count+1;
for i:=0 to NumSTR do
begin
//Заполнение таблицы идентификаторов
str:=memo2.Lines.Strings[i];
form1.StringGrid1.Cells[2,i+1]:=(str);
stringgrid1.Cells[0,i+1]:=inttostr(i);
stringgrid1.Cells[1,i+1]:=Inttostr(VarHash(str));
end;
end;
procedure TForm1.FormCreate(Sender: TObject);
begin
with stringgrid1 do
begin
ColCount:=3;
RowCount:=3;
cells[0,0]:='#Функции';
stringgrid1.ColWidths[1]:=110;
cells[1,0]:='Значение Функции';
stringgrid1.ColWidths[2]:=100;
cells[2,0]:='Строка';
end;
end;
procedure TForm1.Button2Click(Sender: TObject);
var i,n:integer;
begin
find:=0;
n:=VArHAsh(form1.Edit1.Text);
begin
for i:=1 to numstr do
if (strtoint(stringgrid1.Cells[1,i])=n) and (edit1.Text=stringgrid1.Cells[2,i])
then
begin
Find:=Find+1;
form1.Label1.Caption:='Найдено Элементов - '+inttostr(Find);
showmessage('Элемент '+stringgrid1.Cells[2,i]+' найден'+chr(13)+'Найдено Элементов - '+inttostr(Find));
end;
end;
end;
end.
Результат выполнения:
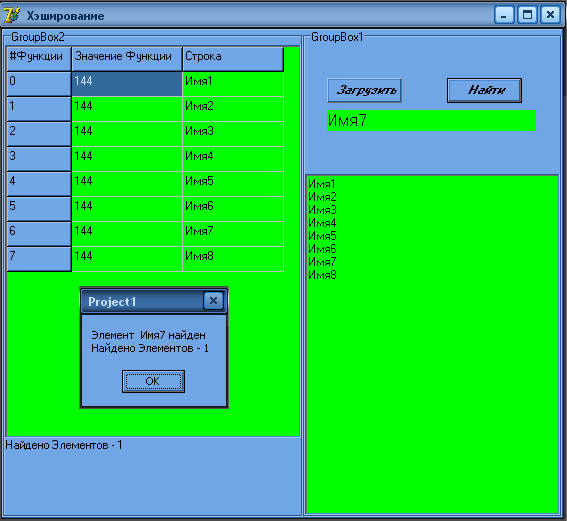
Приложение 2
Задание:
Организовать таблицу идентификатором с помощью бинарного дерева.
Код программы:
Другие рефераты на тему «Программирование, компьютеры и кибернетика»:
Поиск рефератов
Последние рефераты раздела
- Основные этапы объектно-ориентированного проектирования
- Основные структуры языка Java
- Основные принципы разработки графического пользовательского интерфейса
- Основы дискретной математики
- Программное обеспечение системы принятия решений адаптивного робота
- Программное обеспечение
- Проблемы сохранности информации в процессе предпринимательской деятельности