Автоматизированная система регистрации вещественных доказательств
Информационные системы (ИС) служат для сбора и накопления информации с целью ее эффективного использования. На ранних этапах становления информационных технологий задачи автоматизации обработки решались так: для каждого отдельного участка писалась отдельная прикладная программа. В описание программных модулей входили описание структур данных. Однако это привело к значительному увеличению числу
программ, выполняющих сходные функции, но несовместимых друг с другом по данным, используемых программой. Это служило препятствием к написанию больших программных комплексов, а также вызывала сложности в отладке и сопровождении программ. Исходя из этого была разработана концепция баз данных (БД). Основной чертой этой концепции является отделение структур данных от прикладных программ. БД – единое хранилище информации, используемое множеством прикладных программ. Структура данных хранится отдельно от программы для обработки данных. Прикладные программы становятся независимы от данных, которые они обрабатывают.
Предметная область (ПО) - часть реального мира, подлежащая изучению с целью дальнейшей автоматизации. Каждая ПО характеризуется множеством объектов и множеством процессов.
Пример: ПО – бухгалтерия; объекты – документы; процессы - расчет зар. платы, расчет плановой численности и т.д.
СУБД – система управления базами данных. Программная составляющая СУБД включает ядро и сервисные средства. Ядро - набор программных средств, необходимый для создания и поддержания БД. Сервисные средства – обеспечивают дополнительные возможности по управлению данными.
Каждая СУБД поддерживает свой обобщённый инструментарий для отображения ПО, этот инструментария называется моделью данных (МД). Поддерживаемые СУБД МД разбивают на сетевые, иерархические, реляционные.[3]
Жизненный цикл любого программного продукта, в том числе и системы управления базой данных, состоит (по-крупному) из стадий проектирования, реализации и эксплуатации. Естественно, наиболее значительным фактором в жизненном цикле приложения, работающего с базой данных, является стадия проектирования. От того, насколько тщательно продумана структура базы, насколько четко определены связи между ее элементами, зависит производительность системы и ее информационная насыщенность, а значит - и время ее жизни.
Хорошо спроектированная база данных должна удовлетворять следующим условиям:
Удовлетворяет всем требованиям пользователей к содержимому базы данных. Перед проектированием базы необходимо провести обширные исследования требований пользователей к функционированию базы данных.
Гарантирует непротиворечивость и целостность данных. При проектировании таблиц нужно определить их атрибуты и некоторые правила, ограничивающие возможность ввода пользователем неверных значений. Для верификации данных перед непосредственной записью их в таблицу база данных должна осуществлять вызов правил модели данных и тем самым гарантировать сохранение целостности информации.
Обеспечивает естественное, легкое для восприятия структурирование информации. Качественное построение базы позволяет делать запросы к базе более “прозрачными” и легкими для понимания; следовательно, снижается вероятность внесения некорректных данных и улучшается качество сопровождения базы.
Удовлетворяет требованиям пользователей к производительности базы данных. При больших объемах информации вопросы сохранения производительности начинают играть главную роль, сразу “высвечивая” все недочеты этапа проектирования.
Следующие пункты представляют основные шаги проектирования базы данных:
Определить информационные потребности базы данных.
Проанализировать объекты реального мира, которые необходимо смоделировать в базе данных. Сформировать из этих объектов сущности и характеристики (атрибуты) этих сущностей (например, для сущности “деталь” характеристиками могут быть “название”, “цвет”, “вес” и т.п.) и сформировать их список.
Поставить в соответствие сущностям и характеристикам - таблицы и столбцы (поля) в нотации выбранной СУБД (Paradox, dBase, FoxPro, Access, Clipper, InterBase, Sybase, Informix, Oracle и т.д.).
Определить атрибуты, которые уникальным образом идентифицируют каждый объект.
Выработать правила, которые будут устанавливать и поддерживать целостность данных.
Установить связи между объектами (таблицами и столбцами), провести нормализацию таблиц.
Спланировать вопросы надежности данных и, при необходимости, сохранения секретности информации.
3.2 Модели данных: иерархическая, сетевая, реляционная
3.2.1 Сетевая модель данных
Организация МД в СУБД сетевого типа определяется в терминах: элемент, агрегат, запись, групповое отношение, БД.
Элемент - наименьшая единица структуры данных.
Агрегат - именованная совокупность элементов или других агрегатов; Адрес: (ул., дом, квартира)
Запись - агрегат, который не входит в состав никакого другого агрегата и составляет основную единицу обработки БД. Тип записи определяется составом ее элементов.
Групповое отношение - иерархическое отношение между записями двух типов. Записи одного типа являются владельцами отношения, другого - подчиненными.
Групповое отношение при графическом отображении изображается дугами ориентированного графа, в то время как типы записей - вершинами. Такое изображение называется диаграммой Бахмана (рис. 3.1).
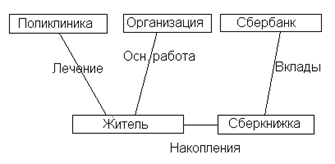
Рис. 3.1.
Сетевая МД поддерживает БД сетевой структуры. В сетевой МД допустимы следующие операции над объектами:
Запомнить - заносит новую запись и автоматически включает в групповое отношение с соответствующей подчиненностью.
Вкл. в групповое отношение - позволяет связать подчиненную запись с соответствующей записью-владельцем.
Переключить - изменяет запись - владельца в том же групповом отношении.
Обновить - изменяет значение элементов записи, перед обновлением соответствующая запись должна быть извлечена
Извлечь, Удалить, Исключить из группового отношения - разрывает связь между записью - владельцем и подчиненным.
Особенности обработки данных в сетевых моделях:
1. Основная единица обработки - запись.
2. Обработка может начинаться с любой записи, независимо от ее расположения в структуре.
3. От конкретной записи возможен переход как к записи - владельцу, так и к записи - подчиненному.
3.2.2 Иерархическая модель данных
Структура данных определяется в тех же терминах, что и у сетевой. Важное отличие от сетевой МД в том, что она может иметь только иерархическую структуру. К каждой записи БД возможен только один путь (иерархический, рис. 2). Сетевая структура может быть преобразована в иерархическую.
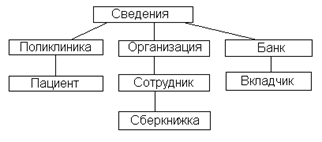
Рис. 3.2.
Операции над данными: Запомнить, Удалить, Обновить, Извлечь.
3.2.3Реляционная модель данных
В реляционной теории одним из главных является понятие отношения. Математически отношение определяется следующим образом. Пусть даны n множеств D1,D2, .,Dn. Тогда R есть отношение над этими множествами, если R есть множество упорядоченных наборов вида <d1,d2, .,dn>, где d1 - элемент из D1, d2 - элемент из D2, ., dn - элемент из Dn. При этом наборы вида <d1,d2, .,dn> называются кортежами, а множества D1,D2, .,Dn - доменами. Каждый кортеж состоит из элементов, выбираемых из своих доменов. Эти элементы называются атрибутами, а их значения - значениями атрибутов. рис. a представляет нам графическое изображение отношения с разных точек зрения.
Другие рефераты на тему «Программирование, компьютеры и кибернетика»:
Поиск рефератов
Последние рефераты раздела
- Основные этапы объектно-ориентированного проектирования
- Основные структуры языка Java
- Основные принципы разработки графического пользовательского интерфейса
- Основы дискретной математики
- Программное обеспечение системы принятия решений адаптивного робота
- Программное обеспечение
- Проблемы сохранности информации в процессе предпринимательской деятельности