Внутримашинное информационное обеспечение управления
Прикладные программы АСУ могут разрабатываться и на одном из универсальных алгоритмических языков (Basic, Visual C++, Fortran, Modula и др.). Однако в таких программах не всегда достигнуть независимости программ обработки и самих данных, избежать дублирования данных в информационных массивах разных задач АСУ. Это приводит к многократному вводу одних и тех же данных для разных задач автоматизиро
ванной системы управления и вызывает существен-ные проблемы при внесении изменений в исходные данные.
Для обеспечения процессов создания и эксплуатации внутримашин-ной информационной базы необходимы соответствующие технологичес-кие инструкции, в которых должны быть регламентированы процессы ввода, контроля данных и корректировки данных, получения копий файлов, архивирования и восстановления базы данных и др. В инструкциях по вводу и контролю должны быть описаны технологии ввода информации, определена последовательность создания массивов. Здесь же должны быть описаны необходимые проверки достоверности вводимых сведений, используемые методы контроля (на диапазон значений, с помощью контрольных сумм и др.).
Инструкции по загрузке и корректировке базы данных должны определять входные документы (массивы), с которых осуществляется загрузка. В этих инструкциях должны быть описаны экранные формы, которые соответствуют формам входных документов и позволяют одновременно вводить данные в несколько логически взаимосвязанных массивов. При этом должны быть обеспечены требования однократного ввода одной и той же информации в базу данных.
Создание базы данных коллективного пользования, в том числе для работы в компьютерных сетях, также должно сопровождаться необходимыми инструкциями для администрации баз данных. В них определяются функции персонала, по обеспечению доступа пользователей АСУ к общей базе данных с соблюдением требований по защите информации от несанкционированного доступа, определению сферы ответственности за сохранность данных централизованной информационной базы АСУ.
3. Организация данных во внутримашинной сфере
Существует два уровня организации данных во внутримашинной сфере - логический и физический. Физическая организация данных определяет способ размещения информации непосредственно на машинных носителях и выполняется программными инструментариями автоматически (без участия человека). Разработчики внутримашинной информационной базы АСУ оперируют в программах только представ-лениями о логической организации данных, которая определяется видом модели данных. Под моделью данных понимается совокупность взаимосвязанных структур данных и операций над этими структурами.
Вид модели и используемые в ней типы структур данных во многом предопределяют выбор системы управления базами данных или языка программирования, на котором создается прикладная программа обработки данных. Следует отметить, что для размещения одной и той же информации во внутримашинной сфере могут быть использованы различные структуры и модели данных. Их выбор возлагается на разработчиков информационной базы АСУ и зависит от многих факторов, в том числе от имеющегося технического и программного обеспечения, объемов информации, сложности задач АСУ.
В ряде случаев при организации данных во внутримашинной сфере применяют файловую модель. При такой модели внутримашинная информационная база представляет собой множество не связанных между собой файлов из однотипных записей с одноуровневой структурой (рис. 4). Запись является основной структурной единицей обработки данных и состоит из фиксированного набора (кортежа) полей, каждое из которых представляет собой элементарную единицу логической организации данных. Структура записи определяется составом и последовательностью входящих в нее полей.
Каждому экземпляру записи, как правило, в соответствие, ставятся один или два ключа записи: первичный (уникальный) и вторичный ключ. Первичный ключ - это одно или несколько полей, однозначно идентифицирующих запись. В случае, если первичный ключ состоит из одного поля, он называется простым, если из нескольких полей - составным ключом. Вторичный ключ, в отличие от первичного, - это такое поле, значение которого может повторяться в нескольких записях файла, то есть он не является уникальным. Если по значению первичного ключа может быть найден один единственный экземпляр записи, то по вторичному - несколько.
Для ускорения доступа к записям файла выполняется процедура индексирования, результатом которой является создание дополнитель-ного индексного файла, содержащего в упорядоченном виде все значения ключей файла данных. Для каждого значения ключа в индексном файле содержится указатель на соответствующую запись файла данных. Наличие индексного файла позволяет по заданному ключу быстро находить запись. Индексирование может производиться не только по первичному, но и по вторичному ключу.
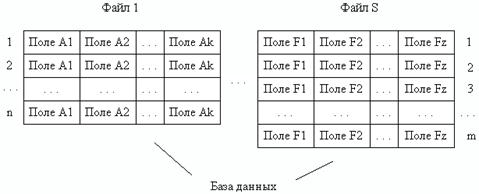
Рис. 4. Файловая организация баз данных (файлы, записи, поля)
Описание логической организации данных файловой модели заключается в присваивании каждому файлу уникального имени, а также в описании структуры его записей. При этом каждому полю задается сокращенное обозначение (имя поля) и указывается формат поля (тип хранимого данного, длина поля и точность числовых данных). Для полей, выполняющих роль уникального (первого) ключа записи, указывается признак ключа. Структура файла обычно описывается таблицей, в которой отмечаются первичные и вторичные ключи.
Файловые информационные базы обрабатываются системами управления файлами (Q&A, Reflex, FFS File и др.), которые не считаются системами управления базами данных. Файловые системы легко осваиваются, достаточно просты и эффективны в использовании. Для работы с ними используются простые языки запросов, либо и вовсе ограничиваются набором программ-утилит. Такие системы обычно поддерживают работу с небольшим числом файлов, содержащих ограниченное число записей с небольшим количеством полей.
Кроме файловых моделей организации данных внутримашинной сферы существуют иерархические, сетевые и реляционные модели. Эти типы моделей являются более сложными и, в отличие от файловой организации данных, поддерживаются СУБД соответствующего типа. Различия между этими классами моделей постепенно стираются. Однако некоторые особенности перечисленных типов моделей следует отметить. Для иерархических и сетевых моделей их структура не может быть изменена после ввода данных, тогда как структура реляционных моделей может изменяться в любое время. С другой стороны, иерархические и сетевые модели обеспечивают более быстрый доступ к информации, чем реляционные модели.
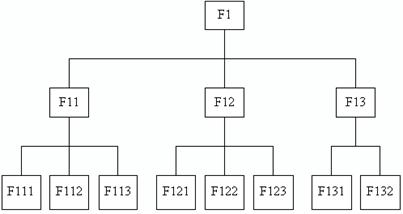
Иерархические модели имеют древовидную структуру, когда каждому узлу структуры соответствует один сегмент, представляющий собой поименованный линейный кортеж данных. Каждому сегменту, кроме корневого, соответствует один входной и несколько выходных сегментов (рис. 5).
Другие рефераты на тему «Программирование, компьютеры и кибернетика»:
Поиск рефератов
Последние рефераты раздела
- Основные этапы объектно-ориентированного проектирования
- Основные структуры языка Java
- Основные принципы разработки графического пользовательского интерфейса
- Основы дискретной математики
- Программное обеспечение системы принятия решений адаптивного робота
- Программное обеспечение
- Проблемы сохранности информации в процессе предпринимательской деятельности