Распараллеливание многоблочных задач для SMP-кластера
1.3 Программирование параллельных ЭВМ
Чтобы считать задачу на параллельном вычислителе, она должна быть распараллелена. Распараллеливать может:
· пользователь - сразу написав параллельную программу. Разработка параллельной программы с помощью специализированного набора средств программирования предполагает либо использование специального языка программирования параллельного компьютера,
либо традиционного языка программирования последовательных машин, расширенного набором спецификаций параллельной обработки данных, либо традиционного языка и библиотеки, реализующей конкретную модель параллельного выполнения.
Для научно-инженерных расчетов применяются следующие модели программирования:
· Модель передачи сообщений
Каждый процесс обладает собственным локальным адресным пространством. Для синхронизации и обработки общих данных используется передача сообщений. Стандартом интерфейса передачи сообщений является MPI.
· Модель с общей памятью
Все процессы разделяют единое адресное пространство. Доступ к общим данным регулируется с помощью примитивов синхронизации. Стандартом для моделей с общей памятью стал OpenMP.
· Модель параллелизма по данным
В этой модели данные разделяются между узлами вычислительной системы, а последовательная программа их обработки преобразуется компилятором в программу либо в модели передачи сообщений, либо в модели с общей памятью. При этом вычисления распределяются по правилу собственных вычислений: каждый процессор выполняет вычисления данных, распределенных на него. Примером реализации этой модели является стандарты HPF1 и HPF2. На модели параллелизма по данным была также разработана отечественная система DVM.
· пользователь вместе со специальной программой-распараллеливателем в автоматизированном режиме - указывая свойства последовательной программы
· автоматический распараллеливатель – он извлекает параллелизм самостоятельно из последовательной программы и распараллеливает ее в автоматическом режиме без участия пользователя
В каждом варианте есть свои недостатки. В первых двух пользователю приходится активно участвовать в процессе распараллеливания (а в первом и вовсе написать новую – параллельную программу), а в третьем зачастую получаются неэффективные результаты.
Подавляющее большинство программ для систем с распределенной памятью в настоящее время разрабатываются в модели передачи сообщений (MPI). Языки, поддерживающие модель параллелизма по данным (HPF, Fortran-DVM, C-DVM), значительно упрощают разработку программ, но их использование очень ограничено. Кардинальные изменения архитектуры ЭВМ (многоядерность, использование в качестве ускорителей графических процессоров) требуют появления новых языков высокого уровня, обеспечивающих более высокий уровень автоматизации программирования, в том числе и при создании многоблочных программ.
Всем используемым на многопроцессорных ЭВМ с распределенной памятью языкам программирования (включая и DVM-языки) присущ один серьезный недостаток – ручное отображение подзадач на процессоры. Для большого количества подзадач и большого количества процессоров сделать вручную эффективное отображение очень затруднительно.
2 Цель работы
Целью данной работы являются следующие шаги по развитию средств поддержки многоблочных программ в DVM-системе:
· обеспечить автоматическое (а не только ручное) отображения подзадач на процессоры
· обеспечить балансировку загрузки процессоров за счет эффективного отображения подзадач с учетом возможности их параллельного выполнения.
3 Постановка задачи
Дана многоблочная программа на языке Fortran-DVM, использующая механизм подзадач DVM.
Требуется разработать и реализовать эффективный алгоритм автоматического отображения подзадач на процессоры; изменить способ кодирования операций отображения и запуска подзадач, чтобы обеспечить использование алгоритма автоматического отображения; сравнить характеристики выполнения исходной программы с ручным отображением и программы с автоматическим отображением.
4 Обзор существующих решений
4.1 Алгоритм сокращения критического пути (CPR)
CPR предложен разными авторами из голландского политехнического университета Delft и французского института INRIA. Сначала алгоритм был разработан для планировщика задач в многопроцессорных системах, где граф задач можно моделировать в виде ориентированного ациклического графа. Существуют и другие подходы для решения такого рода задач (TwoL, CPA, TSAS) [5], но CPR показывает самый приемлемый результат.
CPR можно применить для распределения многоблочных задач (при условии возможности построения ориентированного ациклического графа).
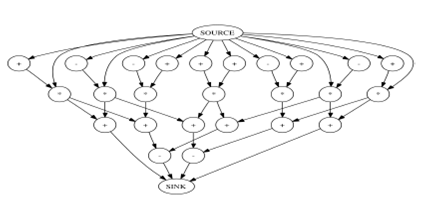
Рисунок 2. Иллюстрация ориентированного ациклического графа блоков
Определение
Критический путь (T): самый длинный путь в графе (от входа до выхода).
Верхний критический путь блока t (Tv): самый длинный путь от входа до t
Нижний критический путь блока t (Tn): самый длинный путь от t до выхода
P - количество процессоров в системе.
N(t) - Количество процессоров, выделенных для блока t.
Описание алгоритма
Шаг 1. Для каждого блока ti выделен один процессор N(ti) = 1. Построить расписание.
Шаг 2. Пусть X – множество всех блоков, для которых выделено меньше P процессоров.
Шаг 3. Пусть блок t – блок, у которого сумма Tv + Tn максимальная.
Выделить для t дополнительный процессор, N(t) = N(t) + 1. Построить новое текущее расписание.
Если после выделения, новый критический путь T’ < T то T = T’, иначе N(t) = N(t) – 1 и блок t исключить из множества X и считать предыдущее расписание текущим.
Шаг 4. Повторяем шаг 3 пока X не пусто
Суть алгоритма состоит в выделении максимально возможного количества процессоров для каждого блока с целью сокращения критического пути (т.е. сокращение общего времени выполнения всех блоков). Данный алгоритм исходит из наличия алгоритма построения расписания.
Алгоритм эффективный, учитывает зависимости между блоками, но не рассматривает проблему назначения групп процессоров для конкретных блоков и составления расписания их прохождения.
4.2 Упаковка в контейнеры
Bin-packin это множество алгоритмов для решения задачи: объекты различных объемов должны быть упакованы в конечное число контейнеров так, чтобы минимизировать количество используемых контейнеров. В нашем случае упаковка в контейнеры используется для равномерного распределения задач по всем процессорам.
Упаковка в контейнеры без разбиения объектов
Имеем список объектов L=(a1, a2, …, an) и их размеры s(ai) Є {1, 2, …, U}. Размер контейнеров V больше U, количество контейнеров m. Отсортируем список объектов по размеру в убывающем порядке. Первые m объектов упаковывать соответственно будем в m контейнеров. С остальными объектами действуем по принципу: упаковывать в контейнер, у которого занимаемого места меньше всего.
Упаковка в контейнеры с разбиением объектов
Существует два возможных варианта упаковки в контейнеры с разбиением объектов [4]: с сохранением и с увеличением объема данных. Будем рассматривать вариант с увеличением объема данных, так как после разбиения часто появляются дополнительные коммуникации между фрагментами.
Другие рефераты на тему «Программирование, компьютеры и кибернетика»:
Поиск рефератов
Последние рефераты раздела
- Основные этапы объектно-ориентированного проектирования
- Основные структуры языка Java
- Основные принципы разработки графического пользовательского интерфейса
- Основы дискретной математики
- Программное обеспечение системы принятия решений адаптивного робота
- Программное обеспечение
- Проблемы сохранности информации в процессе предпринимательской деятельности